Why Every Marketer Needs the Power of SQL: an Interview with Fareed Mosavat (former Director of Product at Slack)
Fareed Mosavat (who has led product teams at some of the hottest PLG companies like Slack, Instacart, and Zynga) shares his experiences leveraging data to unlock product-led growth, any barriers he had to overcome, and where he sees the space moving forward

Zack Khan

Luke Kline
September 15, 2021
9 minutes

Recently, we had the privilege of sitting down with Fareed Mosavat. As an expert in product-led growth (PLG), he’s led product teams at some of the hottest PLG companies like Slack, Instacart, and Zynga. Our goal was to learn about his experiences leveraging data to unlock product-led growth, any barriers he had to overcome, and where he sees the space moving forward.
This interview is for marketers, growth teams, and anyone focusing on turning insights into action. The following is a summarization of our conversation and his perspectives as to why giving marketers access to data gives them the ability to experiment more often and with more granularity.
What are the biggest blockers for Product-Led-Growth and lifecycle marketing?
Fareed: The core challenge in marketing has always been data accessibility. When marketers are waiting on data, they can’t experiment, learn, or iterate, so all of that time is wasted. Compounded growth comes from compounded learning, and compounded learning comes from data being accessible.
Every single time data access is limited within an organization, it doesn’t just slow everything down: it also causes you to only ask certain “risk-averse” questions. To be specific, you end up only asking the questions you think will provide the most value, so all creativity is lost. Typically, the most time-sensitive answers are found in the top 80% of the most common questions (things like “what was our ARR last month?”).
However, the most interesting questions are almost always in the bottom 20%. These are the ones that can only be answered when data is accessible by your business teams; and they are the ones that are completely unique to your business (ex: what is the correlation between the number of emojis sent and long-term retention in Slack? 🤔)
Why is data accessibility so hard?
Fareed: The problem is, all of the information about a customer is often kept in a multitude of disparate data sources; in tools like Segment, Amplitude, Mixpanel, etc, as well as your CRMs like Iterable, Marketo, Salesforce, or Hubspot. All of these tools are necessary, but not sufficient to make good marketing decisions. When your data is scattered everywhere, it makes it nearly impossible to maintain a single source of truth.
This causes everyone in the organization to have a slightly different view of the customer, which means that the customer experience varies from team to team. It also becomes nearly impossible to track all touchpoints with a specific customer because the data is spread out across a variety of different systems. Additionally, when each of your operational systems is showing a slightly different snapshot of your data, you can’t be specific when reaching out to your customers and prospects.
Let’s say a customer demoed a product and clicked on a certain resource. If you can’t fully trust your data because it is potentially out of date or not formatted correctly, then you can’t trigger a highly personalized and automated email specific to the resource they clicked: it will have to be generic instead. Generic outreach usually leads to a lower conversion rate. On the other hand, if you want to send a personalized email, you will have to wait for engineering to set up a new data pipeline to push the product data back into the email system in order to create your email list.
This means your marketing team loses a lot of independence because they are not able to quickly iterate anymore. Relying on engineering pulls away from the time you could be experimenting, running campaigns, and learning from your data. This opportunity cost adds up.
How do you recommend different teams work together to use data and achieve PLG?
Fareed: The traditional names and different functions don’t necessarily apply to most product-led growth companies. The lines between the marketing team and the product team are very blurry. To me, PLG companies struggle with the unification of their various teams. When you don’t have a single holistic view of your data, each of your teams serves the customer differently.
Ultimately, the customer experience is not unified because your different teams are building different experiences with absolutely no visibility or awareness as to what the other teams are doing. This causes your customer to end up receiving a hodge-podge of different information which could have been streamlined if the data was accessible. As the popular quote goes, “Don’t ship your org chart”.
Everyone has a different view of data, a different set of capabilities, and a different set of processes, but they should all have the same goals. Even though we were on different functional teams at Slack, we all worked on the same goals and outcomes. Ultimately, we were organized around common missions of Activation, Monetization, Retention, and Expansion.
Moving data outside of various dashboards helped our different teams stay unified. Dashboards only provide visibility; they don’t automatically drive action and many of them are ignored. Data is only really useful to non-data teams once it is pulled out of a single source of truth (i.e. the data warehouse). By ensuring each of our teams had the data they needed in their specific tools, by pulling the data out of the warehouse and pushing it back into our native operational systems, we were able to stay aligned and reach our shared goals.
How did your various teams at Slack use data to fuel product-led growth?
Fareed: At Slack, we wanted our internal administrative tool to identify who the most active users were based on a variety of different dimensions and factors. This was important because we could see the most active Slack users in different workspaces by measuring things like workspace activity, messages sent, emails sent, invites, and channel creation. In turn, this was super valuable for our sales team because they could leverage this information to tailor their outreach and also identify which people were most likely to respond.
This type of information also provided real-time insights for our individual account executives because we set up internal Slack notifications for them. It also gave visibility into when adoption was accelerating. This gave our sales team the ability to close more deals, expand into more customers, and reach out to the proper people at the perfect time. Ultimately, we found that it was becoming increasingly important for our different teams to have access to the same data.
That is to say, it was really important for our support and product teams to know if a customer was in an active sales deal. There are a ton of little examples, but at the end of the day, everyone in your company needs to be looking at the same picture of the customer and that is only possible with a strong foundation focused on Operational Analytics.
How can companies make data more accessible?
Fareed: Cloud data platforms like Snowflake have made it easier than ever for organizations to establish a single source of truth on their data by consolidating it all into one location. However, when data is moved into a platform like Snowflake, it's not usable by anyone except your data teams because it is only actionable through SQL.
The value of a data warehouse lies in the fact that it removes data silos by consolidating the data from your different sources into one single platform. However, the double-edged sword of a data warehouse is that it creates one giant data silo which is inaccessible by anyone except your data teams.
Reverse ETL solves this problem of data inaccessibility by syncing data from your data warehouse into your operational systems and updating them in real-time as the data is transformed. It democratizes data for additional teams, enabling them to actually put it to work through the power of Operational Analytics in the tools that matter the most (for example, enabling lifecycle marketing campaigns like an automated email to users who abandoned their shopping cart).
I experienced the challenges of data integration firsthand when working at Slack and Instacart. The time it takes to create a new connector or integration for every tool across your marketing stack is a huge time sink that is pulling away from the real job you hired your data engineers for, and locking marketers out of valuable data they need in their tools. This is not even mentioning the work required after one of these integrations is completed. All it takes is one slight update or schema change to break your entire pipeline.
What are the biggest barriers to data accessibility and how should they be overcome?
Fareed: The largest barrier to data accessibility and democratization is SQL. It’s a superpower, but it shouldn’t be a barrier. Interestingly, there is nothing innately special about SQL. It simply gives you the ability to ask questions and get clear answers. The challenge is that a large portion of marketers don’t know SQL, so they have to go through the data teams to answer their questions. This creates a vicious cycle because if you go through an analyst or engineer, the cost of the question goes up because more people are involved, which means more time is being spent. Likewise, if the data isn’t formatted properly, then follow-up questions take even longer and cost even more.
Any tool that gives marketers the power of SQL without needing to know it is crucial. A great example of a tool that is doing this today is Hightouch Audiences. Hightouch Audiences gives you the ability to visually define and filter audiences in an intuitive point-and-click UI without needing to know any SQL. Best of all, it is done directly on top of the data models built within your data warehouse. This is exactly why this new feature is so valuable: it gives marketers and business teams superpowers. Ultimately, Hightouch Audiences enables marketers to have self-serve access to data, leading to more experimentation, creativity, and ROI within marketing teams. Tools like this are the future.
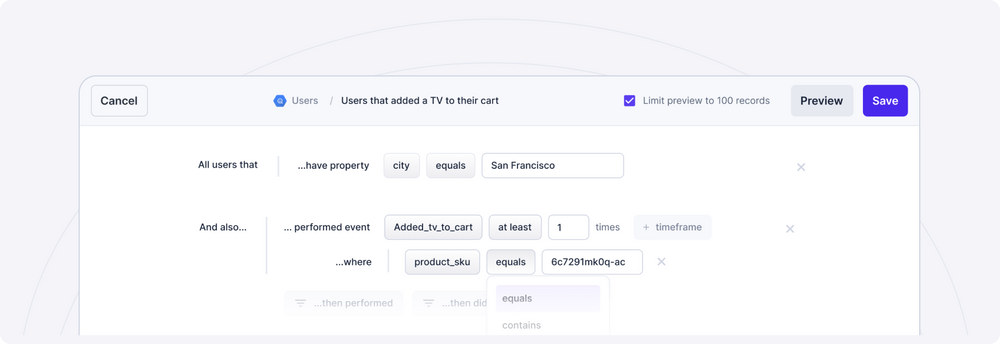
If SQL is no longer required, it means that your marketers can now ask any question or series of questions; which in turn means that they can experiment and create ad hoc campaigns in the blink of an eye to accelerate lifecycle marketing campaigns, target paid ads, create lookalike audiences, send conversion events, etc.
Until marketers are given the ability to self-serve their data, we will remain in this vicious cycle of restrained creativity and growing opportunity cost every single time marketing asks a question.
What to read next?
If you're interested in increasing data accessibility in your org, check out Hightouch Audiences and book a demo here. And if you are interested in learning how to unlock product-led growth, be sure to read Hightouch's definitive guide on How to Use your CRM for PLG