What is Treasure Data CDP?
Learn everything there is to know about Treasure Data, including products, key features, real-time capabilities, and pros/cons.

Luke Kline
March 18, 2024
12 minutes

If you’ve been working in data or martech for any amount of time and you’re evaluating enterprise CDPs, then you’ve probably stumbled across Treasure Data. It’s one of the oldest Customer Data Platforms (CDPs) on the market today.
In this blog post, you’ll learn everything there is to know about Treasure Data, including:
- What is Treasure Data?
- Core Products and capabilities
- Key features like data collection, storage, modeling, identity resolution, and audience management
- Real-time capabilities
- Reverse ETL
- Security
- Pros and cons
What is Treasure Data?
Treasure Data is a CDP tailored towards developers and enterprise companies that helps you collect and transform all of your data so your marketers can build custom audience segments to deliver personalized experiences across channels.

The company didn’t actually start out as a CDP; it was founded in 2011 by Hironobu Yoshikawa and Kazuki Ohta as a big data platform designed for enterprise companies. Treasure Data pivoted into the CDP space after realizing most of the use cases the platform was powering were for marketing teams. The platform then subsequently rolled out features for profile unification, segmentation, and activation.
Given how old the tool is, it comes with quite a lot of tech debt because it was built in a different era. The compute engine is powered by Presto and Hive, which are mostly seen as legacy technologies that have fallen out of favor with data engineers as next-gen offerings like Snowflake have emerged.
Core Products and Capabilities
Treasure Data has a lot of features and capabilities, but the crux of the customer data offering is built around five key features:
- Data Collection allows you to collect and ingest data into Treasure CDP. The platform offers pre-built connections and integrations for traditional data sources like third-party systems and production databases to bring data into the platform and software deployment kits (SDKs) that you can implement across your websites, mobile apps, and servers to capture behavioral data.
- Profile Unification enables you to run data transformation jobs and custom data models to perform identity resolution to de-duplicate and merge customer profiles.
- Audience Segmentation lets your marketers build and create custom audience cohorts through a no-code interface, using data models your engineers have made available within Treasure Data.
- Experimentation and Analytics shows you metrics about your segments so you can measure performance across audiences and campaigns.
- Activation gives you the ability to sync audience cohorts directly to your downstream operational tools so you can create targeted campaigns across channels.
To actually make use of any of these features, you have to spend a lot of engineering resources in the implementation phase setting up Treasure Data. Under the hood, Treasure Data is more akin to a legacy data warehouse than a CDP–which is redundant for the majority of companies that already have or are in the process of migrating to more modern, fully managed cloud data warehouses like Snowflake or BigQuery.
Data Collection
For data collection, Treasure Data supports batch ingestion for standard data sources and real-time ingestion for event tracking that you can deploy on both the client and server sides. You can manage all of these data pipelines as jobs within the platform through a user interface or command-line interface (CLI) that provides a log of your queries and data imports.
Event forwarding (or the ability to route behavioral data directly to downstream destinations) does not appear to be supported in the platform. Within the pipelines themselves, there is little ability to transform your data, so all data is still in its raw form when ingested into Treasure Data. If you actually want to leverage your data for analytics or activation use cases, you’ll need to do a significant amount of modeling and transformation once your data is available in the platform.
Data Storage
Treasure Data operates as a traditional CDP, which means all of your data is stored natively within the system. The platform is built on top of a data lake architecture that’s powered by Hive and Presto. This architecture is powered by a lot of tech debt and legacy technology that’s not super scalable or user-friendly. Implementation and ongoing maintenance are very challenging. All of your data is stored in databases or tables, which have to be set up by your data team–and each table can only belong to one database.
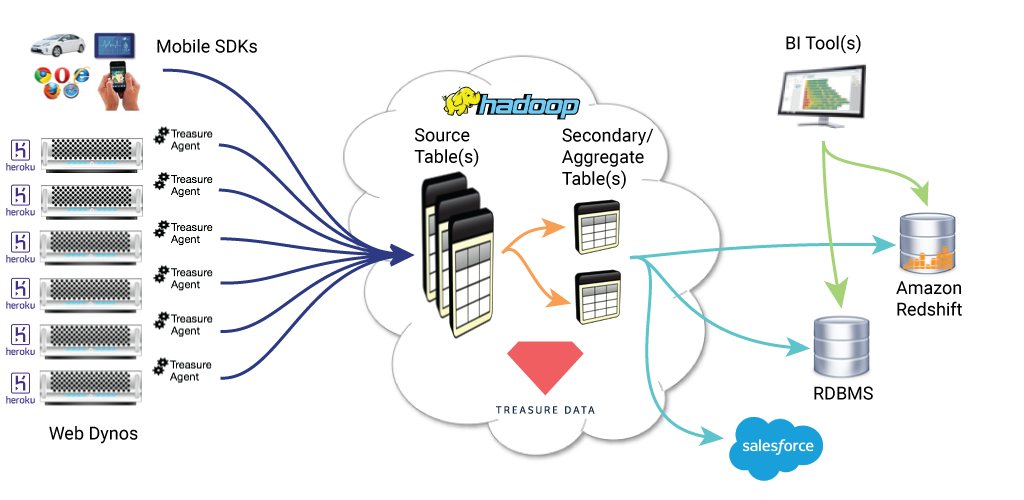
One of the major downsides to this architectural approach is you end up creating two separate sources of truth: one in your data warehouse and another in Treasure Data. Inevitably, this means you’ll end up paying for duplicate storage costs and forcing your data team to manage two separate datasets. This is one of the many reasons companies are transitioning to Composable CDPs to leverage and build on top of their existing data infrastructure.
Data Modeling
Treasure Data has a lot of features designed for data engineers, specifically for data transformation. All transformation jobs are powered by the data workbench, which gives you the ability to manage queries, workflows, and other database activities around schema management and identity resolution.
Schema Management
Treasure Data’s schema uses the same framework as a typical Relational Database Management system (RDBMS). The actual structure of the schema is much more flexible than other traditional CDPs because the platform doesn’t have pre-conceived notions about how your data should be structured as long as it falls into one of the following table structures:
- User Identity: name, email, address, etc.
- User Attributes: age, income, gender, etc.
- User Behavior: purchases, last login, page views, etc.
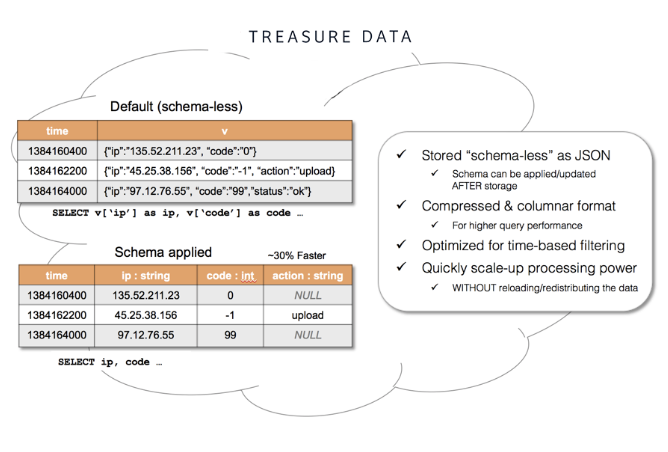
The bad news is this means you have to set up and build a new schema once your data is available within the platform. With a Composable CDP, you can skip this entire process and simply leverage the existing data assets in your warehouse. This architecture circumnavigates these complexities so your marketers can take advantage of all the custom data models your data team has already defined in your warehouse. The benefit of this is that your data team doesn’t have to maintain data across two systems, and your marketing teams build audiences using any and all of your data–not just the sources that have been ingested into Treasure Data.
Identity Resolution
Like many other traditional CDPs, Treasure Data also provides a suite of features to perform identity resolution so you can merge and de-duplicate known and anonymous users to create a single picture of your customer. Profile unification in Treasure Data works by looking at all of your unique identifiers to merge profiles based on the rules that you define via workflows. This is most likely done using a combination of both deterministic and probabilistic matching algorithms to unify your profiles across various the tables and data models you’ve built on the platform.

Once your profiles have been unified, Treasure Data creates a unification database where you can access all of your customer profiles. One important factor to note is that this feature is highly technical and not currently usable by marketers as it stands today. In fact, the documentation even says: “While it was created for marketers, you will likely need a developer on your team to implement some of these features, which can utilize Treasure Data Workflows.”
Another problem with this capability is that you don’t actually own your identity graph because it only lives in Treasure Data, and that means you can’t leverage it for other use cases outside of marketing. With a Composable CDP, your identity graph lives directly in your data warehouse, which means you own it from end to end.
Audience Management
Once your data has been modeled and unified in Treasure Data, your marketers can build segments using the Audience Studio, a no-code interface for creating audiences of users and customers based on attributes, events, and user-defined traits.
To actually create these audiences, though, your data team first has to define a parent segment (or data model) within Treasure Data. Underneath this parent model, you can define both batch audiences and real-time audiences. Batch audiences contain historical data and customer attributes, and real-time audiences contain streamed behavioral events. Batch audiences are only refreshed once the parent segment is refreshed, whereas real-time audiences are constantly processing and updating.
After you’ve defined these audiences, you can sync data to downstream operational tools through direct integrations that Treasure Data manages on your behalf. Due to the legacy nature of the platform, some of your data syncs will not be able to run until enough resources are available within the platform, and all data syncs must be managed via individual workflows, which quickly becomes unscalable for high volumes of data.
From a feature standpoint, Treasure Data does have some interesting capabilities to support journey building and experimentation, but again, none of these features are accessible without a lot of support from your data team.
Real-time Capabilities
Every CDP is flaunting real-time capabilities these days, but the standard for what it means to be real-time is often different across use cases and companies. In the context of Treasure Data, the platform offers three features to support real-time use cases:
- Real-Time 2.0: This feature enables you to unify your profiles in real-time as events stream into Treasure Data.
- Real-Time Triggering: This feature allows you to automate processes in the platform via workflows when users take specific behavioral actions across your website, mobile app, or server so you can automatically enroll them in journeys.
- Real-Time Personalization: This feature is powered by Treasure Data’s Profile API. Instead of syncing data out of the platform, you to make requests to this API and pull in data and attributes so you can deliver personalized content and power on-site experiences.
Reverse ETL
If you need to sync data out of a data warehouse outside of Snowflake, like Redshift, BigQuery, or Azure Synapse, Reverse ETL is not supported within Treasure Data. Currently, you have no ability to leverage data storage outside of Treasure Data, which means the platform cannot sync data directly from your warehouse to destinations. In order to actually sync data, you first have to ingest it into Treasure Data.
Many companies are now realizing it doesn’t make sense to store data in an entirely separate platform that operates in parallel to their existing data warehouse, especially since the data warehouse often has the most complete definition of your customer.
Given this demand, it’s only a matter of time before Treasure Data integrates with other data warehouses. However, the tightly coupled architecture of the platform will make it very difficult for Treasure Data to fully decouple all of their features to make them available in a warehouse-native fashion.
Security
For security, Treasure Data is very similar to other CDPs on the market, such as Segment, mParticle, Amperity, ActionIQ, etc. You can set up granular controls to manage user access and permissions. Additionally, all of your data is encrypted in transit and at rest using AES 256 encryption. Other features like audit logs are also available so you can easily track changes made by users, and you can deploy multi-factor authentication (MFA) and single sign-sign-on to manage resource access.
You can also configure the platform to be GDPR, HIPAA, and CCPA compliant, but not without a substantial amount of effort. Storing your data outside of your cloud infrastructure within another vendor will always open you up to some level of risk. The best way to maintain security is to leverage your existing storage, which is another reason reason why many companies are now switching to the Composable CDP.
Pros and Cons
While Treasure Data checks all the boxes for what it means to be a CDP, the platform is more tailored toward data teams than marketers, so it definitely has its upsides and downsides. Here’s a list of some of the biggest pros and cons of the platform to keep in mind as you evaluate CDPs.
Pros
- Strong support for Japanese-specific brands/companies
- Data engineering & analytics functionality
- AI/ML capabilities
Cons
- Not marketer-friendly (built for data teams)
- Architecture is built on legacy technology (Presto & Hive)
- Requires substantial data engineering resources to implement & maintain
- Identity graph is owned by Treasure Data
Closing Thoughts
Treasure Data has been around for a long time, and as such, it comes with a lot of architectural baggage from a pre-cloud world. The platform itself was initially built for data engineers–not marketers. Most of the companies still using Treasure Data today are doing so because of vendor-lock-in.
If you’re looking for a modern alternative that integrates with your existing data infrastructure, consider Hightouch. It’s a Composable CDP that gives you all the benefits of a traditional CDP and allows you to use your own modern data warehouse as the foundation of your customer data. If you’re interested in learning more about how Hightouch can help you, book a demo or talk to one of our solution engineers today.