What is Identity Resolution?
Learn how to create a 360-degree view of your customer by stitching user profiles together in your data warehouse.

Nate Wardwell
May 30, 2023
13 minutes
Every day, marketing and data teams find themselves asking: "What did my customers actually do?" While it's easy to look at specific metrics like revenue in aggregate, understanding what an individual customer did is more complex. Real customers will engage with your brand using different devices, both online and offline, and across multiple channels.
To personalize outreach to customers and drive sales, marketers and advertisers need to fully understand a customer's actions, regardless of when or how that action occurred. Tying together actions and attributes across devices and channels into a full view of a customer is the critical challenge that identity resolution solves.
What is Identity Resolution?
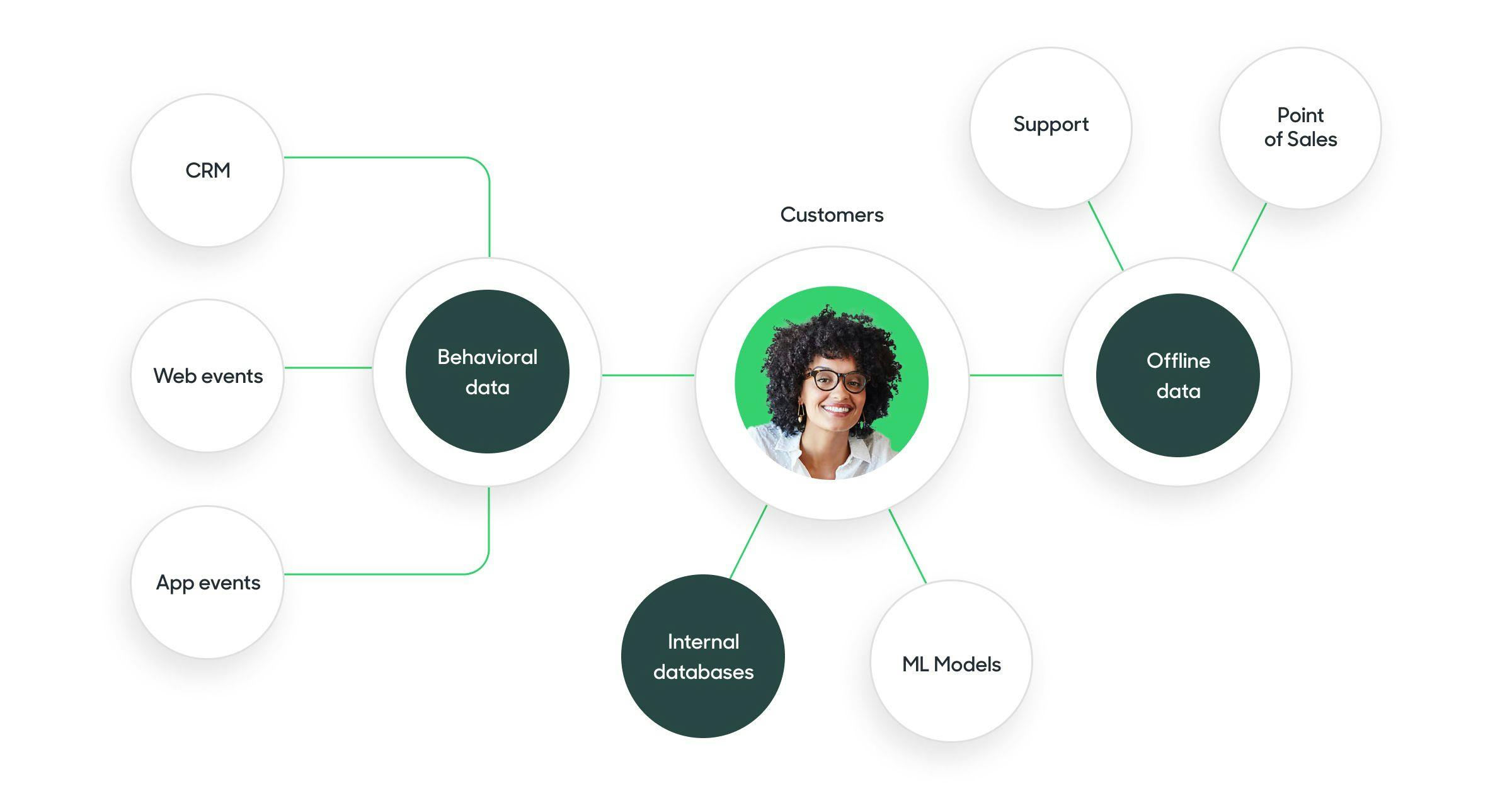
Identity resolution is the process of stitching together user actions and attributes across multiple touchpoints and systems. The purpose of identity resolution is to tie all of your data, both offline and online, together so you can link every behavioral action to a specific customer or user profile to better understand the many actions your customers are taking.
Identity resolution is a crucial component of data onboarding. It begins with the raw data you collect about your customers as they browse your site online or engage in person with your brand so you can link customer identifiers across different systems and touchpoints. This allows you to create a 360-degree view of your customer interactions, enabling you to better understand and engage with them in the future.
What’s the Difference Between Identity Resolution and Entity Resolution?
Entity resolution is an umbrella term for stitching together disparate records that should all be aligned to a single profile. Identity resolution is an example of entity resolution, where the records that are stitched together are individual user records. Entity resolution can be used on other non-user records, such as accounts, to remove duplicate data and standardize records.
Entity resolution can help you look at customers in aggregate groups rather than as individual users. For example, a cable service may want to standardize all customer actions within household entities rather than individual users. The cable company is not selling to each discrete member of a household but instead to the entire household, and so rather than focusing on customer identity resolution, the cable company will work at a higher household level. Similarly, a company that sells software to other companies may care about identities at the account level rather than worrying about individual users from within a client's account.
We've written a separate article about entity resolution, but the fundamental approaches for identity resolution and entity resolution are similar.
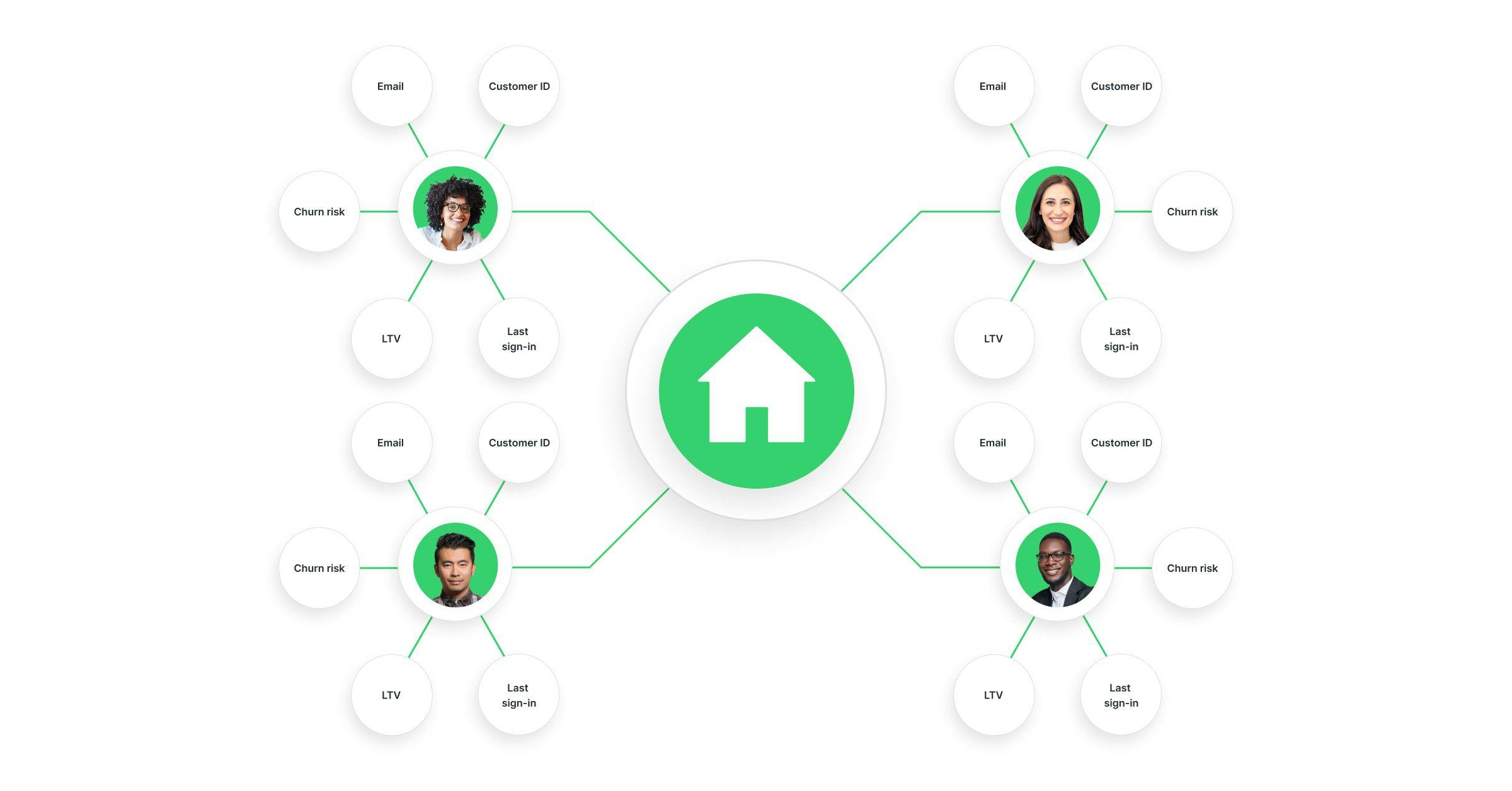
How Does Identity Resolution Work?
At a high level, the steps to build a customer 360 view based on identity resolution are:
- Create Identity Graphs. Identity Graphs are tables of known customer identifiers, that provide a “map” of how a company can stitch together customer interactions.
- Consolidate customer data. Companies use their Identity Graphs to link and deduplicate different customer actions.
- Link entities to customer data. Companies link other entities, such as households, to each individual customer profile.
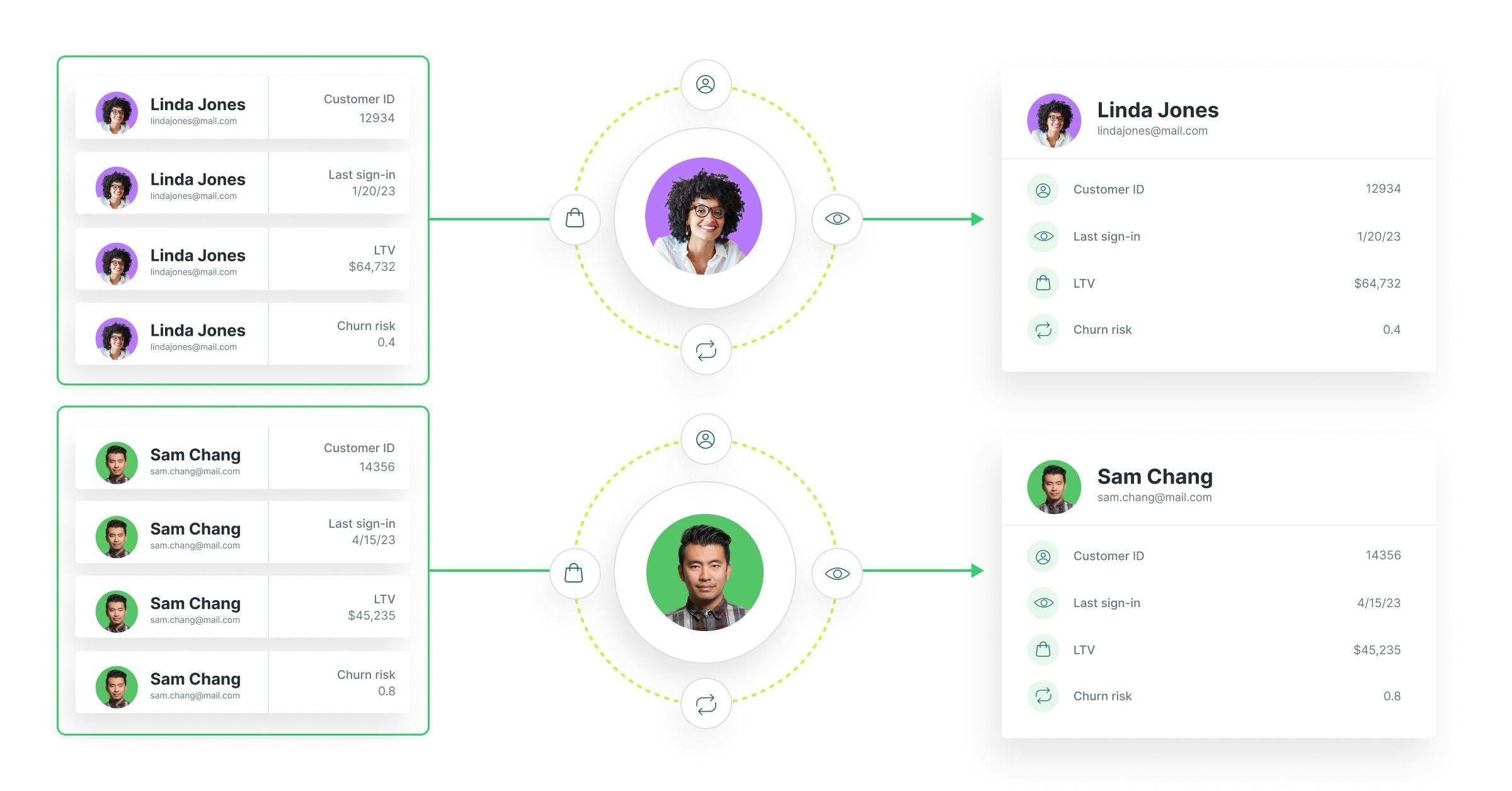
Why Does Identity Resolution Matter?
While identity resolution is mainly focused on building a single customer profile, there are many other important downstream implications.
Benefits of Identity Resolution
By solving identity resolution, you can fully understand how customers interact with your brand and build a Customer 360 view. This deeper understanding of customers allows you to:
- Personalize the entire customer journey across ad channels, onsite/in-app experiences, or even in-store experiences
- Improve data quality for decision-making and analytics
- Comply with privacy regulations by keeping all customer records together so they can be easily managed
- Improve security by making it easier to identify fraudulent users
Identity Resolution Use Cases
While there are a near-limitless number of use cases that identity resolution can power, the list below should provide some practical use cases for building personalized experiences across channels and devices.
- Create More Accurate Product Recommendations: Get a complete picture of every product a user has interacted with to improve onsite product recommendations through messaging channels like email, SMS, and push notifications, and in paid remarketing ads.
- Enhance Omnichannel Marketing: Identify users who interacted on one device and remarket to them via other channels and on different devices. For example, If a user leaves items in an e-commerce cart on their desktop, you can send a push notification to their mobile device with a personalized offer to get them to complete their purchase.
- Improve Ad Suppression: Identify customers who have subscribed to your service and suppress them in future ad campaigns. This is especially important for pixel-based remarketing ad campaigns where you’re remarketing to seemingly anonymous site visitors who may be existing subscribers using a new device.
- Join Online and Offline Experiences: Identify customers who shopped online but tend to shop in-store so you can drive better, more informed marketing campaigns like mailing them a physical coupon vs. sending another email.
- Uplevel Analytics: By joining user sessions and actions together, you can more easily analyze cross-channel and cross-device user behavior to gain deeper insights into customer journey performance.
Identity Resolution’s Growing Importance for Privacy and Compliance
In addition to personalization, significant trends of increased regulation and customer demands for privacy and security have increased the importance of strong identity resolution for organizations.
More states and countries are adopting regulatory frameworks around CCPA, HIPAA, and GDPR that require companies to notify customers when they collect their data, provide customers with copies of their stored data, and sometimes even delete it. Identity resolution creates consolidated customer records, which can facilitate these requests for data transparency or deletion. When your customers opt out of marketing messaging, identity resolution can also help ensure that you truly stop reaching out to them across all your digital touchpoints.
This singular view of a customer can also be used in security and fraud prevention. Understanding when a single user tries to open multiple accounts, uses numerous credit cards with different zip codes, or takes other strange actions can help you identify and block fraudulent users.
Types of Identity Resolution
There are only two types of identity resolution: deterministic and probabilistic. Each is fairly different from the other.
1. Deterministic Identity Resolution
Deterministic identity resolution stitches together customer actions using first-party data that the customer has provided, such as when they login to your website. Deterministic identity resolution is meant to be as near as possible to 100% accurate because it’s not based on any assumptions but instead based on explicit customer actions.
For example, suppose a customer purchases in-store using their personal loyalty-rewards number and later browses the site on a desktop while logged in. Deterministic matching will stitch those activities together to the same customer profile. If the customer was not signed in while browsing, their anonymous browsing data would not be linked to their profile.
Deterministic identity resolution is valuable when high accuracy is required, such as to deliver personalized emails and messages across lifecycle marketing channels.
2. Probabilistic Identity Resolution
Probabilistic identity resolution uses predictive algorithms to stitch together customer actions. Unlike deterministic identity resolution, it’s not based exclusively on highly accurate first-party customer data signals such as logins. Still, it can use other signals like similar identifiers or actions from the same IP address, location, and wifi network. This is sometimes referred to as "fuzzy matching" identity resolution.
For example, if an anonymous customer browses your brand's desktop website from the same wifi network that a known customer is logged into the app on, a probabilistic model could assume that these two actions are from the same known customer and link them to the same customer profile.
A big callout is that probabilistic matching is less accurate than deterministic methods. However, it can lead to more matches. You can customize your tolerance for accuracy with your own predictive models and tailor them to your needs.
Probabilistic vs. Deterministic Identity Resolution - Which is Right for You?
Realistically, a sophisticated business should be leveraging both forms of identity resolution in different use cases. For highly personalized messages, the accuracy of deterministic identity resolution is essential for success. For broader goals like building audiences in advertising platforms, the greater power of probabilistic identity resolution will lead to more impactful campaigns, even if some individual customers are incorrectly linked to actions others have taken. Ultimately, different business units should rely on different identity resolution models depending on their needs for fidelity and reach.
Many companies resolve identities within their own data warehouses using transformation tools like dbt. As an alternative, you can use several tools to solve identity resolution. Many of these tools allow you to work within your data warehouse. In contrast, others, like packaged Customer Data Platforms (CDPs), will build their own Customer 360 views from identity resolution within just the CDP. This rigid approach enforces a one-size-fits-all model that doesn’t align to your unique use cases. Leveraging one or even multiple identity resolution strategies within your data warehouse will allow you to achieve the greatest results.
How to Implement Identity Resolution?
The sections below take you through the questions you need to resolve to build an identity resolution solution from start to finish.
What are Identity Graphs?
An Identity Graph is essentially a table that logs all identifiers for a customer. For example, organizations commonly use identity graphs to match user profiles across their many systems on similar digital identifiers like email addresses. By matching disparate profiles on a common known identifier, you can understand user actions at a holistic profile level.
Additionally, some identity resolution solutions support joining anonymous identifiers. When a customer comes to your site without logging in, your digital tracking solution should assign them an "Anonymous ID." Suppose that customer logs back in at any point during their session. When this happens, you can link that Anonymous ID to their known Customer ID in your Identity Graph and tie together their previous behaviors.
Lastly, advanced Identity Graphs can log other data points to enable fuzzy probabilistic matching, such as matching on name and physical address combinations. Regardless of how it's being used, the Identity Graph fundamentally works as a "map" for different identifiers associated with each customer.
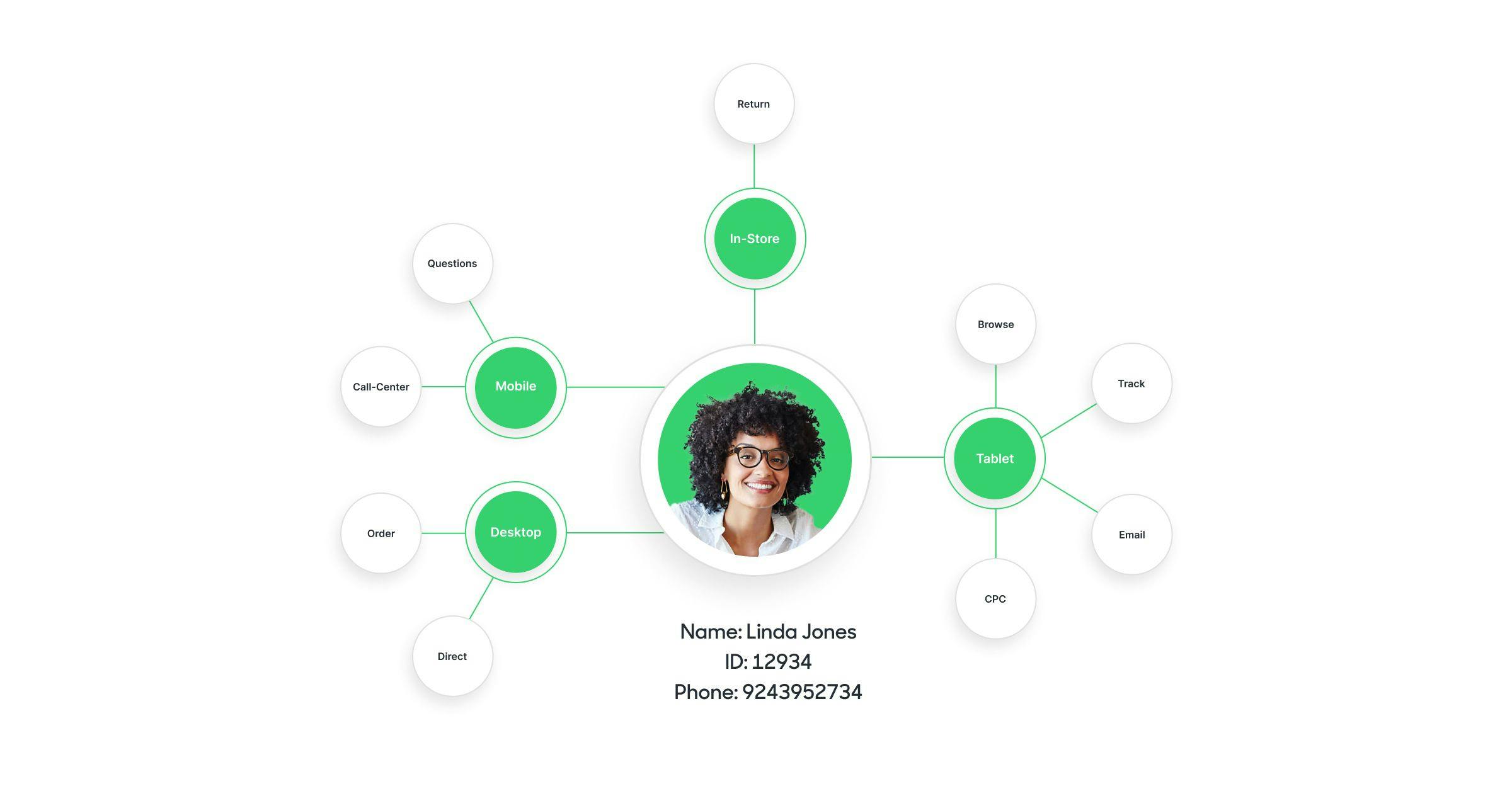
How Do I Use Identity Graphs to Unify Customer Data?
This is the critical step of identity resolution: unifying disparate customer records into a singular customer record by referencing the Identity Graph to understand which customer to assign them. The process of consolidating and deduplicating this data can be solved by your data teams with modeling tools like dbt within your data warehouse. Alternatively, you could buy bespoke identity resolution tools.
How Do I Link Other Entities to My User Data?
Building an accurate 360-degree view of your customer means linking other entities within your data to your customer records. For example, you likely have separate records for purchases. In this case, you’ll want to connect each of these entities back to your customer so you know how many purchases your customer completed and what they bought.
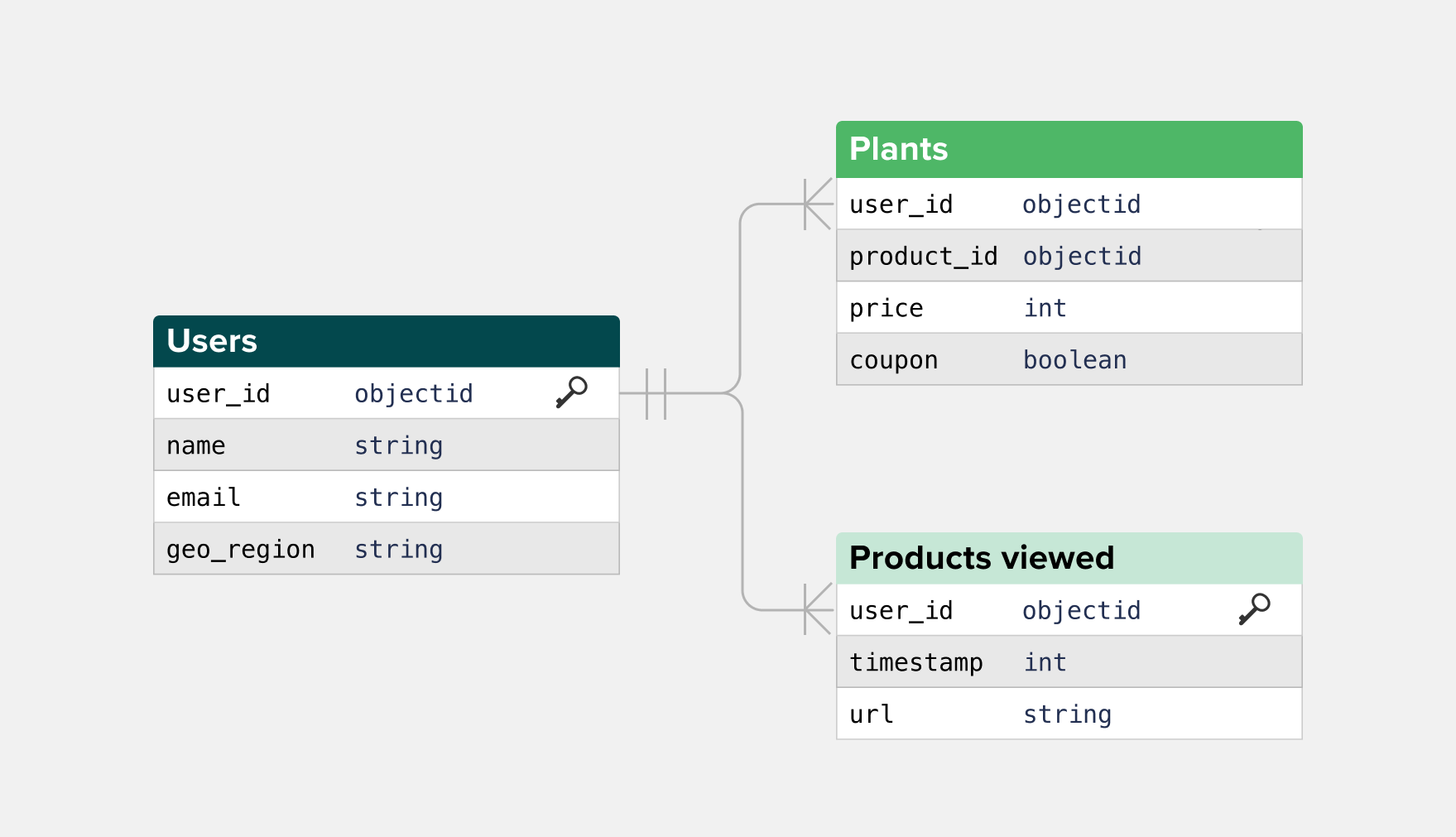
Mapping out the different relationships between users and business entities is known as Business Object Modelling. This can be represented visually in an Entity-Relationship Diagram (ERD) so you can better understand the entities you need to link to your customer data to finish building a 360-degree view of each customer. The ERD example below shows how an online plant retailer might connect its user table with other entities the company has stored.
What Tools Help With Identity Resolution?
If your company has a data team, you can resolve identities directly in your data warehouse. You can use SQL to build custom identity graphs for probabilistic and deterministic identity resolution, consolidate user records, and associate other entities to each consumer identity.
For companies without the technical resources or time to build their own identity resolution solution, there are solutions to buy. Warehouse-first identity resolution strategies give companies the most flexibility and power as they develop modern data systems. These allow companies to leverage all of the data in their warehouse to build robust identity graphs. There are a few critical warehouse-first products that you can lean on to assist your data teams in identity resolution, notably including:
- Hightouch offers an Identity Resolution feature that allows users to define precise rules to resolve multiple identity graphs within any data warehouse.
- Zingg is an open-source entity and identity resolution provider that works natively on warehouses like Snowflake and Databricks.
- Truelty is an identity resolution solution explicitly designed to deduplicate identities within Snowflake instances.
Traditional CDPs fall short by handling identity resolution through their rigid systems. They typically have specific logic that they rely on for identity resolution that cannot be tailored to each company's specific environment.
Furthermore, these rigid identity resolution systems fail to support more robust entity relationships, such as the household a customer belongs to. Finally, legacy CDPs only resolve identities within the CDP itself–not in your data warehouse. If you want to see any offline or historical events in your Customer 360, a CDP will provide an incomplete picture - leaving gaps in your overall understanding of customers.
Final Thoughts
Companies need a 360-degree view of customer actions to best connect with each customer. Companies rely on various methods to unify customer records, regardless of how or when the customer interacted with the company. Each company relies on different tiers of fidelity to resolve customer identity: personalized messages rely on high accuracy, while broad advertising campaigns grow more effective with more aggressive though less accurate identity resolution. Ultimately, a data-mature company should develop a suite of identity resolution approaches from the rich, unified data stored in their data warehouse.
Finally, companies need to act on this rich Customer 360 view they have built. Hightouch helps companies activate data directly from their warehouse to tools that support marketing and advertising, empowering business users to put this rich customer data to work efficiently in over 200 downstream tools. To learn more about how Hightouch can help, talk to a Hightouch Solutions Engineer to build a plan to model and activate your data.