Modernizing ETL in the Cloud Data Warehouse
Why data teams should replace legacy ETL with a combination of ELT and Reverse ETL.

Amit Kapadia

Luke Kline
June 8, 2023
11 minutes

We’ve spoken to countless organizations that face significant challenges when it comes to integrating their data effectively. The dissatisfaction with legacy ETL (extract, transform, load) platforms like Informatica is widespread.
Recognizing this universal struggle has prompted a shift towards adopting cloud-warehouse-centric data pipelines, which entails replacing traditional ETL with a combination of ELT and Reverse ETL. In this blog post, we will explore why the conventional ETL approach is now considered outdated and why adopting ELT and Reverse ETL offers many benefits for achieving optimal data integration with cloud data warehouses.
A Quick History of ETL
For the last 20+ years, traditional ETL practices have remained largely unchanged, with the most popular tools like Informatica, Oracle, Talend, IBM DataStage, Microsoft, SISS, HVR, etc., dominating the data pipelining world.
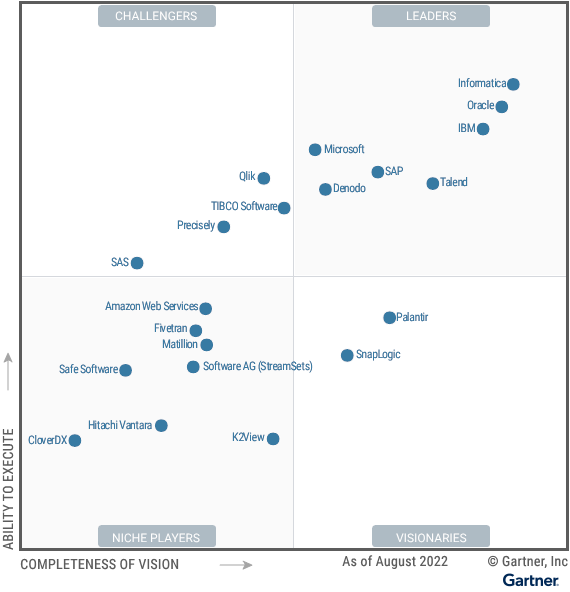
Source: https://www.gartner.com/doc/reprints?id=1-2AWA2A6O&ct=220822&st=sb
Most, if not all, of these technologies, pre-date the cloud and were primarily designed to address on-premise databases. While every ETL technology claims to have its own unique features, they generally offer a similar low-code interface where data teams can define their ETL logic and orchestrate data flows using a drag-and-drop, graphical user interface (GUI) to join, filter, aggregate, and map data between different systems.
For most ETL use cases, the final destination tends to be a data warehouse, but in many scenarios, organizations often require data synchronization with frontline business tools to power their customer-facing use cases. Although legacy ETL platforms can do this, they weren’t originally built for use cases in the cloud. These workflows are often cumbersome and loaded with years of technical debt. As a result, organizations resort to creative workarounds to address various edge cases that inevitably arise.
The Love/Hate Relationship with ETL
Few sane data engineers today would willingly purchase a legacy ETL tool. Traditional ETL tools are implemented by top-down management decisions who have long-standing relationships with these vendors spanning over two decades.
The Love Relationship
The reason these platforms are so popular amongst enterprise organizations comes down to a few core factors:
- Familiarity: ETL platforms have existed since the early 1990s, so most companies using them have deep in-house domain knowledge and experience. Many data engineers will include titles like “Informatica/Talend Developer” in their job descriptions.
- On-prem Support: Many enterprise companies still rely on the multitude of on-premises applications and databases, and traditional ETL platforms were designed to seamlessly interact with these systems.
- Pricing: ETL platform pricing is often based on user licenses, making cost predictions relatively straightforward. For example, Informatica offers a starting price of $2,000 per seat. While pricing may have some small nuances, this user-based model holds true for all legacy ETL tools.
- GUI-based: GUI-based controls - simplify onboarding and training processes, enabling users to build very simple pipelines while maintaining existing ones.
- Existing Relationships: Most companies running on Informatica or Oracle have long existing relationships with vendors that go back 20+ years, which makes testing or evaluating new technologies very difficult.
- Flexibility: Data integration platforms can write back to a data warehouse or directly back to various operational systems, allowing them to address several different use cases within a single platform.
- Tool Consolidation: ETL platforms handle all aspects of data integration, such as writing to a data warehouse or operational tools. This allows companies to manage all of their data pipelines using a single tool suite within one platform.
The Hate Relationship
These legacy products were designed decades ago. In fact, many of them are still installed locally, relying on client applications for their execution. Platforms like Informatica and Talend rely heavily on GUIs, which makes it impossible to maintain proper version control or establish a single source of truth for business logic.
These platforms also limit custom transformations. Business logic is housed in out-of-the-box transformation components, which means transformations are limited to the capabilities of the platform. Any custom SQL transformations must be contained within their own component to fit into the strict GUI ecosystem.
Additionally, legacy tools make it very difficult to analyze and update models. Because the transformation step takes place within the ETL platform, data teams are often left with limited visibility into how the data should be modeled before it’s ingested. Inevitably this causes data teams to perform additional transformations after the data is ingested into the warehouse.
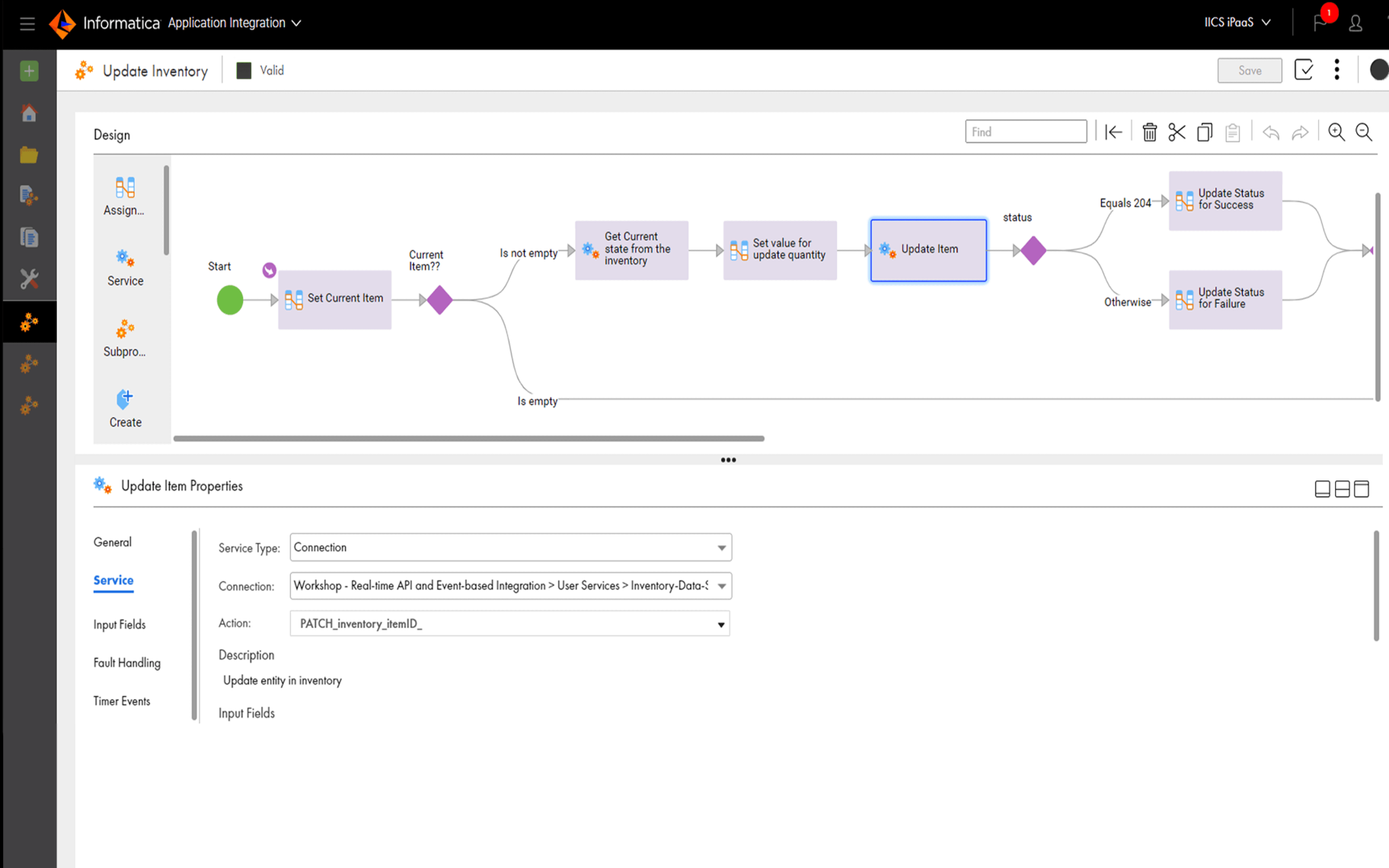
Legacy ETL platforms work from rigid GUIs
This legacy data integration architecture has several additional negative drawbacks:
- Vendor-lock-in: Traditional ETL providers lock organizations into a single platform, making it extremely challenging for organizations to rip and replace. These platforms are designed to be general-purpose and lack the flexibility needed to address business-specific use cases.
- Code limitations: GUI-based pipelines impose strict contingencies on business logic since all code resides within GUI-based components. This affects the ability to implement custom logic and adapt pipelines to evolving requirements.
- Scalability: Since all ETL pipelines are defined by visual drag-and-drop components, a single change to an end system or ETL component can have unintended consequences across the entire workflow, which makes overhauling business logic a nightmare for data teams, as every individual component requires updating, introducing complexity and potential errors.
- Outdated Software: Most ETL providers have only recently rolled out cloud-native versions of their products, and migrating existing workflows and business logic to these updated platforms can be a painful and time-consuming process. These legacy platforms are riddled with technical debt, hindering efficiency and performance.
- Cost: Legacy ETL platforms are incredibly expensive, especially for large companies that need to support many users and pipelines. These expenses can quickly escalate, placing a strain on the organization’s budget.
- Imperative operations: ETL platforms are imperative. Data teams are responsible for explicitly defining, building, and maintaining all of the various dependencies in their pipelines. The alternative would be a declarative system where data teams could simply point data toward their end system and define the desired end state. This is perhaps the core reason that data teams are moving away from the traditional ETL and adopting ELT and Reverse ETL.
The Rise of Warehouse-Centric Pipelines
Prior to cloud data warehouses, traditional ETL platforms served as the primary means to transform and pipe data into organizational systems. The cost constraints associated with transforming data within a data warehouse made it an impractical approach. However, the cloud data warehouse has completely shifted this paradigm.
Previously only the largest organizations with substantial technology budgets could afford the performance, flexibility, and scalability needed to securely load, integrate, analyze, and share data in the cloud–that is, until Snowflake up-rooted the data ecosystem by introducing a paradigm shift. By separating storage and compute, introducing usage-based pricing, and creating the first fully managed SaaS-based cloud data platform, Snowflake democratized data accessibility.
Simultaneously, as cloud data warehousing was taking off, the data engineering field experienced a transformative shift. Data teams realized they could directly transform data in their warehouse with SQL–and thus, the shift from ETL to ELT began with a little company called Fishtown Analytics and the introduction of dbt™.
Very few people had any idea how “transformative” (no pun intended) this tool would become for data teams as they leveraged it to automate data transformation by compiling and running SQL directly in their data warehouse. Prior to dbt, data teams had no way to manage and run SQL queries centrally.
This effect was further amplified when Fivetran introduced fully-managed connectors that automated data replication from a wide range of data sources into various data stores. With Fivetran handling the underlying maintenance tasks such as schema normalization and table structures, data teams were liberated from the complexities associated with traditional ETL workflows.
Building on this momentum, data engineers realized the need to activate data from the warehouse. This led to the creation of Reverse ETL platforms like Hightouch, allowing data teams to deliver clean, transformed data directly from the warehouse to hundreds of downstream operational tools in minutes. Instead of having to define point-to-point data flows in a GUI, data teams could simply activate the existing models in their data warehouse and sync that data directly to their frontline business tools.
What previously had to be one giant individual pipeline defined in an ETL platform could now be centrally managed around the data warehouse using a customized, unbundled approach. And for the first time ever, data teams no longer needed to predict how their data should be modeled for their future use cases before ingesting the data.
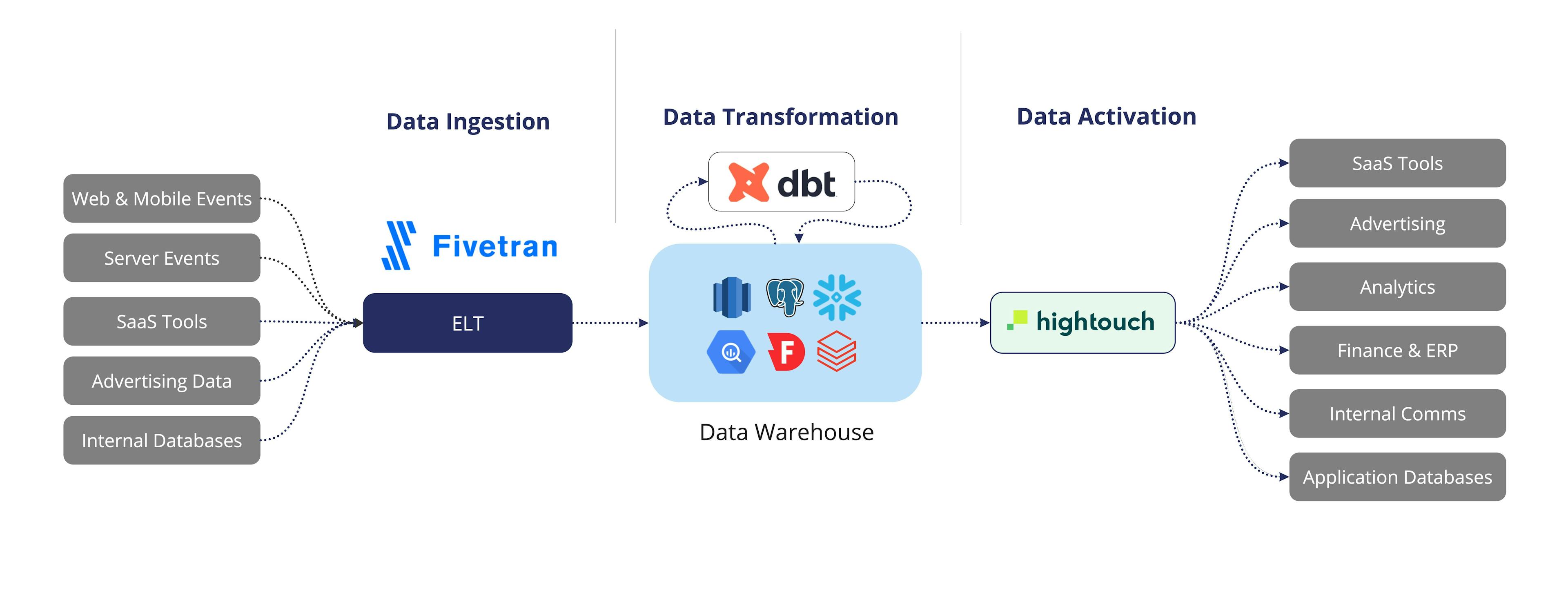
The Benefits of Unbundling ETL
The adoption of a warehouse-centric approach to data pipelining offers several advantages over traditional ETL:
- Speed: Ingesting raw data directly into the warehouse eliminates the need to consider data modeling upfront, resulting in significantly faster data ingestion and more accurate data models.
- Flexibility: Transforming the data directly within the warehouse enhances efficiency by standardizing business logic and enabling the reuse of data models for various use cases.
- Transformation: Warehouse-based transformation is unencumbered by the limitations imposed by ETL providers. Data teams have the freedom to write SQL or leverage other development languages, empowering them to query and explore data before performing any transformations.
- Maintenance/Scalability: Writing SQL to update business logic is faster and easier to debug compared to maintaining individual workflows where each individual component needs to be updated.
- Data accessibility: Centralizing all data models within the warehouse ensures easy access and reuse for analytics and activation purposes, enabling efficient data utilization across the organization.
- Version Control: Hightouch and dbt integrate natively with Git so data teams can easily maintain, roll out, and roll back changes to business logic, all while ensuring that everyone is working off of the same code.
- Activation: Centering data flows around the warehouse enables organizations to rapidly activate warehouse data at scale, whether that’s syncing data to Salesforce, Hubspot, Braze, Iterable, Google Ads, Facebook, etc.
Tools like Fivetran, dbt, and Hightouch were purpose-built to handle a specific slice of the modern data stack continuum: Fivetran handles extraction and ingestion, dbt tackles transformation and modeling, and Hightouch addresses Data Activation. These tools work together to streamline the data pipeline process and optimize data integration within the warehouse-centric approach.

With the evolution of the modern data stack, data teams are able to seamlessly bundle together best-in-class tools to solve their specific use cases. These tools support warehouse-first methodology, reusable code and standardized business definitions, Git version control, and scalable development practices. By building modularly, teams can execute at a high caliber without jeopardizing business-critical processes or customer trust.
Rachel Bradley-Haas
Co-Founder
•
BigTime Data
How to Convince Your Organization to Change
While modernizing data pipelines is a common goal for enterprise organizations and data practitioners, securing buy-in from management can be challenging. Fortunately, most technology implementations at the enterprise level involve an extensive proof of concept (POC) process. This presents a significant advantage for data teams looking to modernize ETL pipelines, as Fivetran, dbt, and Hightouch all offer free tiers in a self-service model.
By demonstrating “quick wins” with the modern data stack, data practitioners can influence data architecture strategy. Here’s an example of what this might look like in practice:
- Replace an existing “Salesforce to Snowflake” pipeline in Informatica with a fully automated Fivetran sync, eliminating manual processes and streamlining data integration.
- Use dbt to build a lead scoring model in your data warehouse, leveraging the power and flexibility of SQL-based transformations.
- Activate the lead scoring model using Hightouch and sync that data back into Salesforce, enabling sales reps to prioritize leads effectively.
Companies in all industries have already adopted this warehouse-centric approach to data integration and witnessed huge benefits, particularly in Data Activation use cases. Here are a few examples:
- Warner Music Group leverages Snowflake and Hightouch to power thousands of audiences for activation.
- Lucid improved ROAS by 52% and reduced engineering time by 12.5 hours per integration.
- IntelyCare saved $1 million in marketing spend.
Final Thoughts
The traditional ETL approach is no longer suitable for managing data pipelines in the evolving cloud-native ecosystem. Data teams can accomplish better results by leveraging their existing SQL skills and performing transformations directly in the warehouse rather than being confined to a legacy tool’s rigid GUI designed for use cases from twenty years ago. Embracing declarative systems, where data destinations are defined rather than manually defining every step, enables faster process and agility.
Combining Fivetran, dbt, and Hightouch establishes a “write once, use anywhere” ecosystem, eliminating the need to model data twice. ELT platforms like Fivetran efficiently ingest data into the warehouse, while dbt simplifies the transformation process using SQL. Finally, Hightouch activates the transformed data to downstream tools. It’s time to unbundle your legacy ETL platform and work with these best-in-breed players to modernize your data stack.
It takes an average user just 23 minutes to set up their first sync with Hightouch. Speak to a solutions engineer today to get started with proof that you no longer need a legacy ETL platform.