Overview
At Hightouch, we work with large healthcare, financial, and public enterprises to sync sensitive customer data to downstream tools and systems. As such, we're committed to building a data activation tool that's held to the highest possible security standards.
This document gives an overview of our security processes and infrastructure architecture. It outlines your options for data transfer and storage, including implementing Hightouch so that none of your data is stored at rest on Hightouch's infrastructure.
Compliance

Hightouch complies with SOC 2 Type 2, HIPAA, GDPR, CCPA, and Privacy Shield.
In addition to these certifications, we follow these security best practices:
- Automated vulnerability scanning in our platform
- Regular third-party penetration testing—please for the latest report
SOC 2 Type 2 audit report
If you are an existing Hightouch customer, or ping us in your dedicated Slack channel to request our SOC 2 audit report. If you are trialing Hightouch, your point of contact can provide you with the SOC 2 audit report under NDA.
Architecture overview
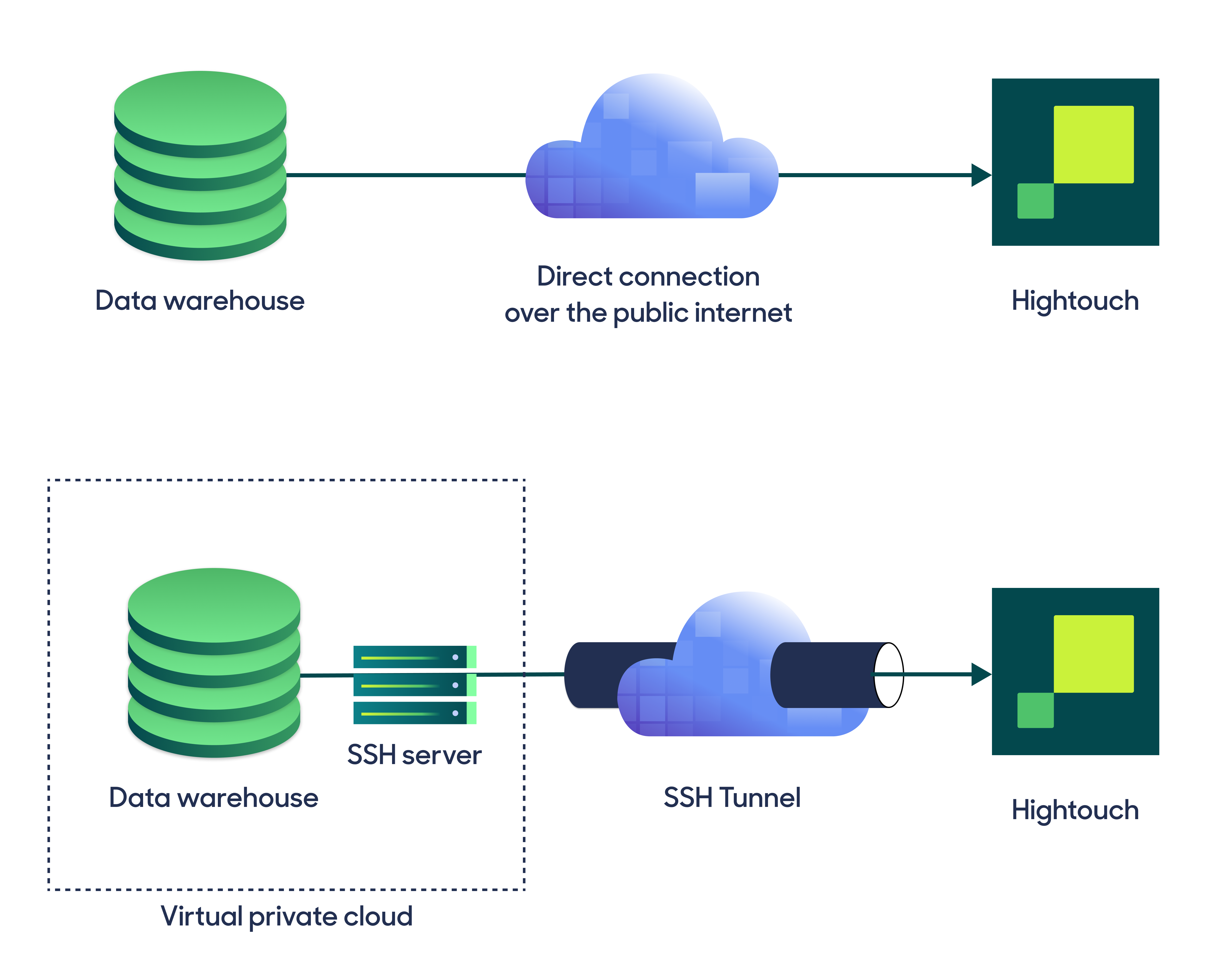
Hightouch can connect to your warehouse or data source directly or via an SSH tunnel or reverse SSH tunnel. A direct connection is suitable for most use cases. If your source is on a private network or virtual private cloud (VPC), you may need to set up a tunnel or use AWS PrivateLink.
Once you've connected Hightouch to your data source, you need to create models that define what data to pull from your source. These data models are purely SQL definitions and do not store data.
A sync declares how to map data to a destination and how often it should run. When a Hightouch sync initiates, Hightouch:
- executes the SQL query associated with your model on your source
- identifies the incremental changes to send to the associated downstream tool
- and translates these rows to the appropriate APIs
For more information on your infrastructure options in this process, refer to the change data capture section.
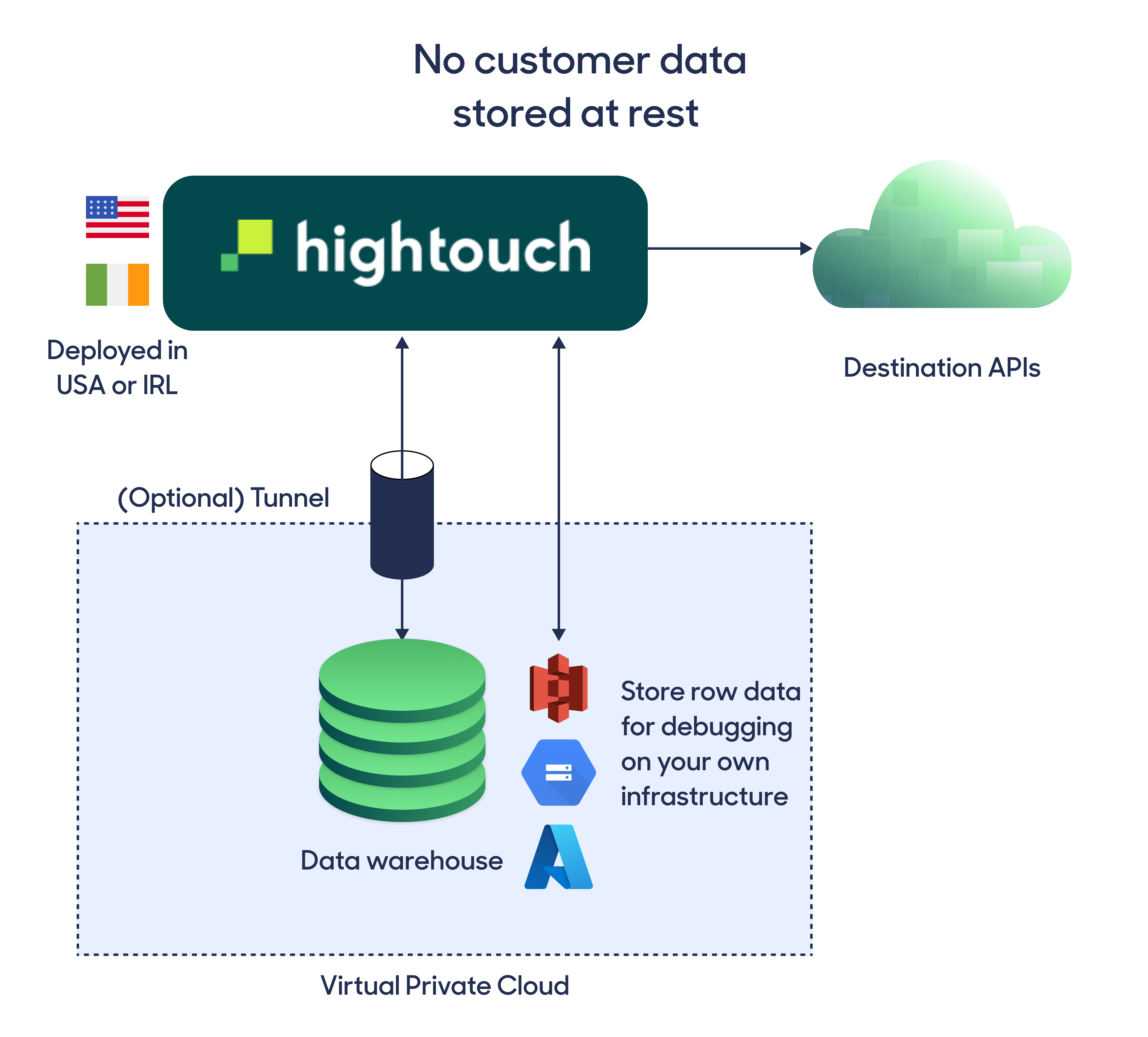
Customer data flows through Hightouch infrastructure only during an "active sync." The data is encrypted in transit via TLS as it's flowing through Hightouch. We don't expose our compute instances to the internet, and we secure our infrastructure according to cloud security best practices.
Transit details
Hightouch uses the Elastic Load Balancer within AWS to distribute incoming traffic across multiple healthy targets and increase application and network availability. To enhance the security of our Application Load Balancers (ALBs) and Network Load Balancers (NLBs), we require that all load balancers that accept HTTPS traffic use at least TLS 1.2.
Older TLS versions and legacy SSL protocols have known fatal security flaws and don't provide protection for data in transit. Hightouch also follows the AWS Well-Architected Framework to achieve best practices related to operational excellence, security, reliability, performance efficiency, and cost optimization.
We use the following best practices for protecting data in transit:
- Enforcing encryption in transit
- Authenticating network communications
- Automating detection of unintended data access
- Using AWS PrivateLink if required
Data storage
After sending data downstream, Hightouch stores full request/response payloads in a cloud storage bucket. By default, this storage bucket is on Hightouch-managed infrastructure, but you can use your own cloud bucket within your infrastructure. Our live debugger queries this cloud bucket for row-level debugging, and if you're self-hosting these logs, you can set custom retention policies.
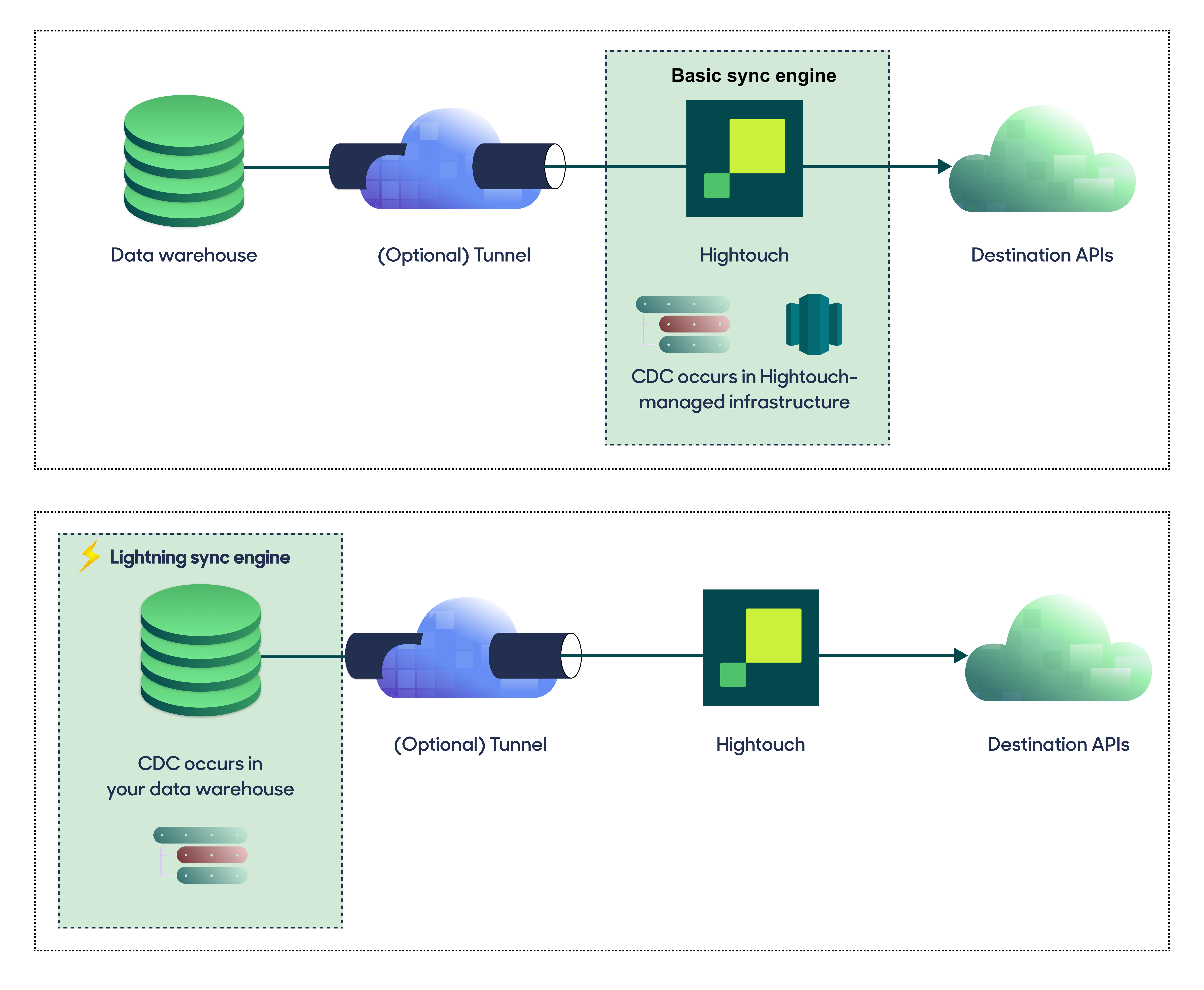
Change data capture architecture
To prevent making excessive API requests and send only necessary updates to your destinations, Hightouch uses a process called change data capture (CDC) or diffing. For details on this process, check out the change data capture docs.
Two different methods are available to support this process, and it's your choice which one you'd like to use:
- The Lightning sync engine does the diff computation within your data warehouse. To allow this, Hightouch needs
WRITEaccess to specific tables in your warehouse that store metadata from previous syncs. In-warehouse computation allows for faster syncs at higher volumes, and customers syncing over 1 million rows typically use the Lightning sync engine for performance reasons. - The standard sync engine, also known as "local diffing," is the default method. The diff computation is done on Hightouch infrastructure, so it has slightly slower sync speeds but has the benefit of offloading some compute from your warehouse and not requiring
WRITEaccess.
Bring your own bucket
On our self-service plans, Hightouch stores your query results in an encrypted cloud bucket on your behalf with a 30-day retention policy.
On our business-tier plans, you can host your own bucket on your AWS, Google Cloud, or Azure instance for more control over your data. Please for details on getting access to this feature.
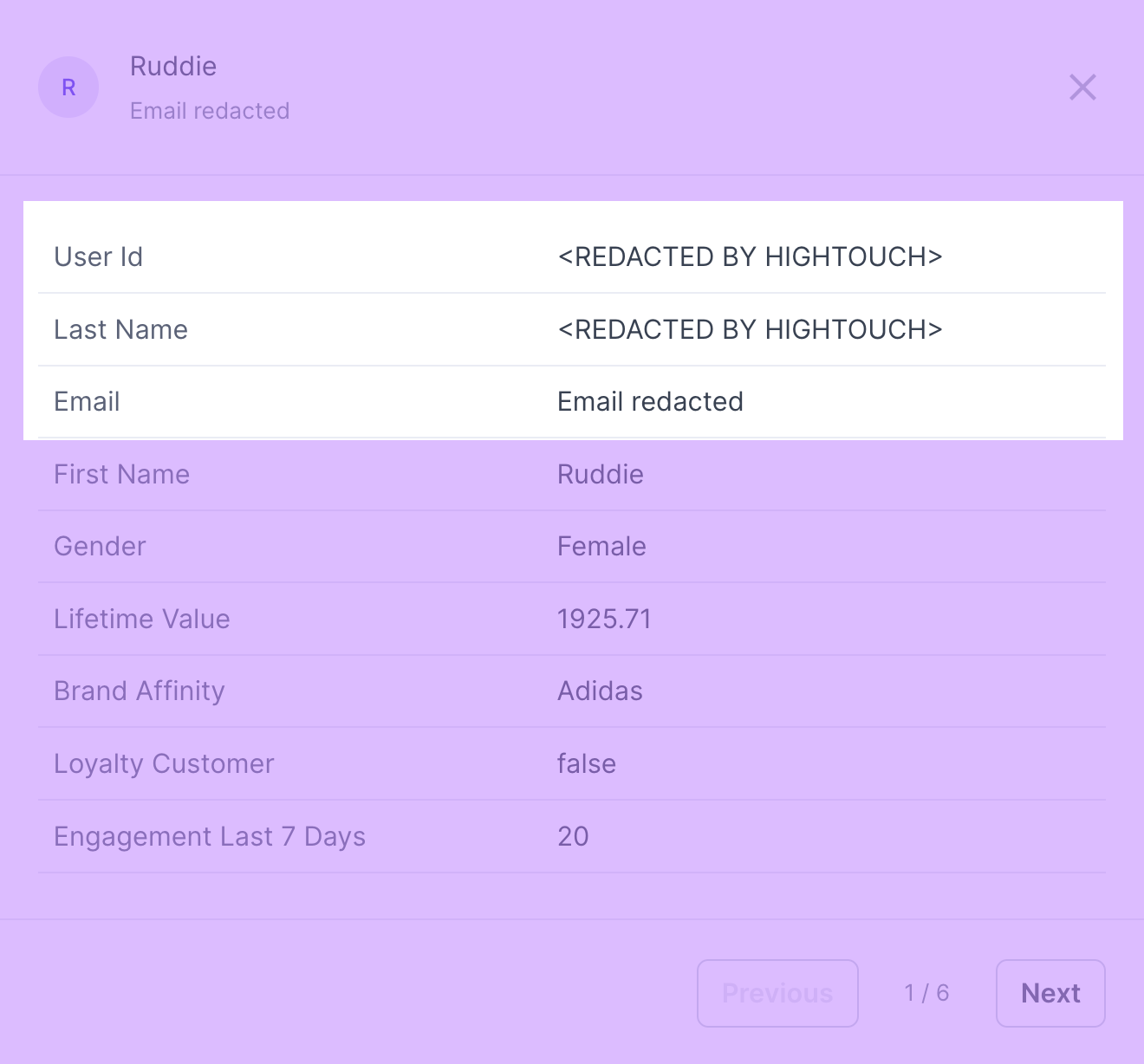
Personal identifiable information redaction
Sometimes, you need to sync Personal identifiable information (PII) to a destination, but you don't want your entire team to have access to it. For example, you may need to sync PII to ad platforms for the most accurate targeting. You may also want your marketing team to build audiences for these destinations, but want to keep them from having access to the PII of those audiences.
When configuring your audience models, you can redact specific columns to hide their values from team members building and previewing audience membership.
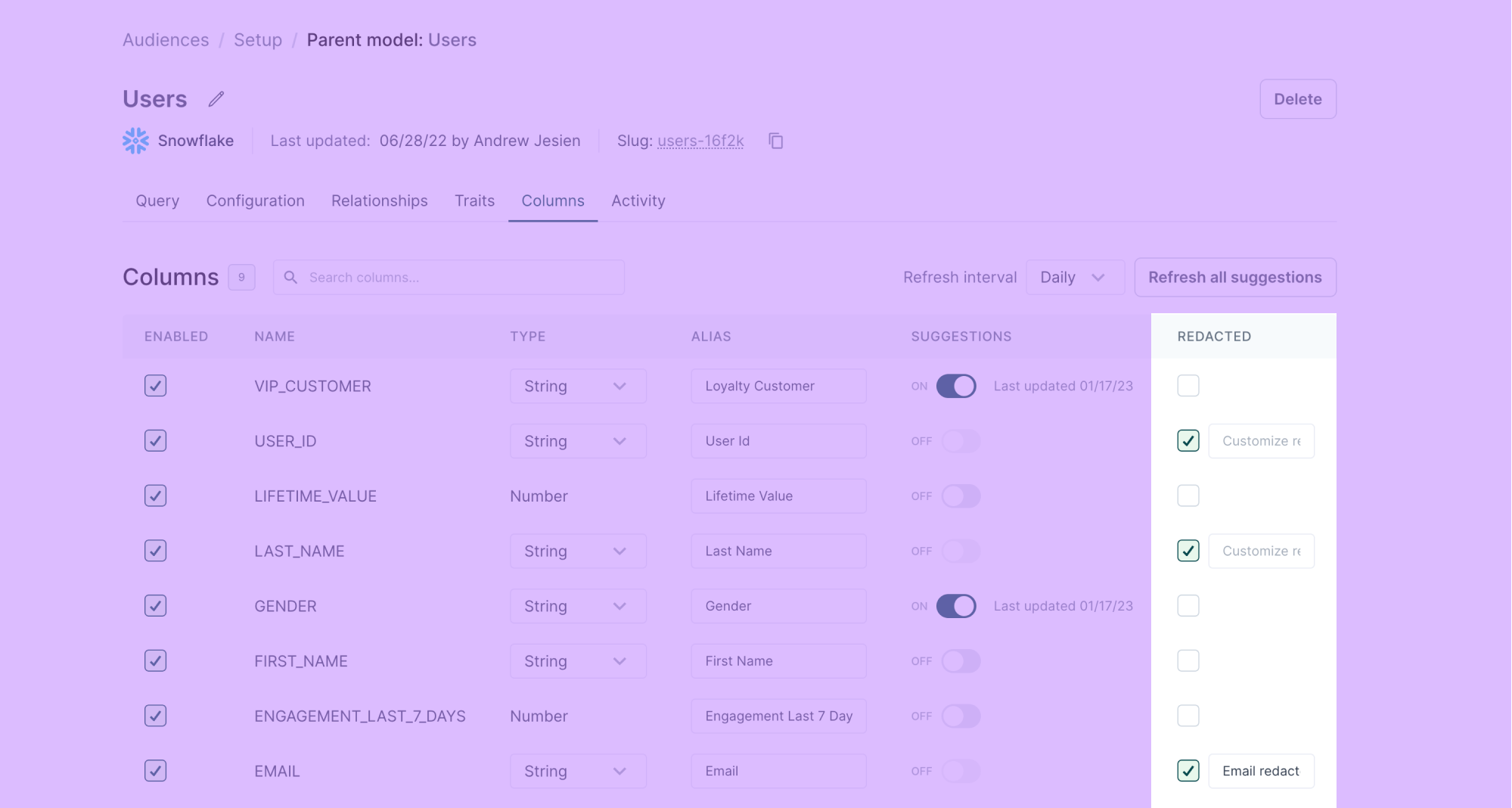
When a team member previews a user using Audience Insights tools, they see <REDACTED BY HIGHTOUCH> or a customized message of your choosing, for example, Field redacted.