Hightouch is a Data Activation platform that syncs data from sources to business applications and developer tools. This frees up valuable engineering time for your data team and delivers actionable data directly to business teams. It also ensures data consistency across your organization.

Keep reading to gain a high-level understanding of Hightouch's core concepts.
Sources
A source is wherever business data is stored. The most frequently used sources include data warehouses like Snowflake and Google BigQuery. Sources can also be databases, CSV files, SFTP, or BI tools.
To add a source to your Hightouch workspace, go to the Sources overview page and click the Add source button.
Destinations
A destination is any tool or service you want to send source data to. They're where end-users typically consume data. Hightouch integrates with 200+ destinations, including CRM systems, ad platforms, marketing automations, and support tools.
To add a destination to your Hightouch workspace, go to the Destinations overview page and click the Add destination button.
Models
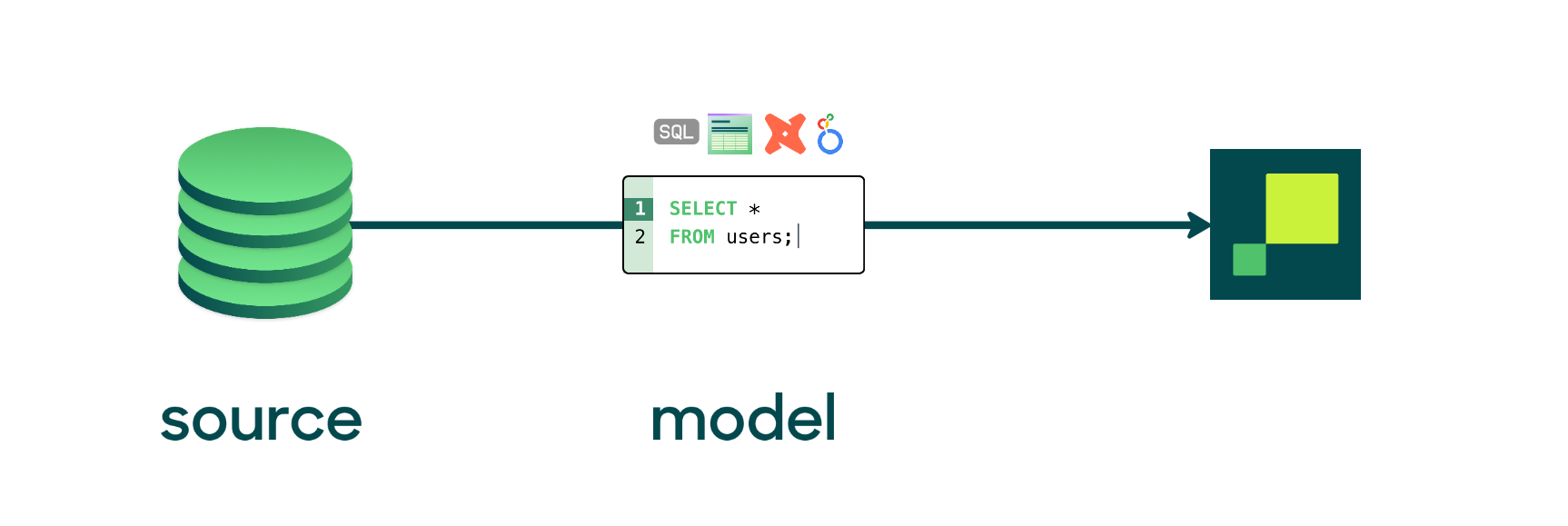
For Hightouch to know what data to sync, you need to create a model. Models define the data you want to pull from a source.
You can define models by:
- writing a query in the SQL editor
- using the visual table selector
- or leveraging existing dbt models or Looker Looks
You can also use Hightouch's no-code Customer Studio feature to define cohorts before syncing data to a destination. Each cohort acts as a segmented model.
Unique primary key requirement
Regardless of how you build your models, you must configure them with a unique primary key. A primary key is a special value used to uniquely identify each row in a dataset. It's like a unique ID for each entry in a table or dataset.
For example, if you have a table containing customer information, you might have a column named CustomerID that contains a unique number for each customer.
Hightouch uses this unique identifier to keep track of records. Using a unique key lets Hightouch only sync new and updated data to your destinations. See the change data capture section to learn how Hightouch accomplishes this.
Syncs
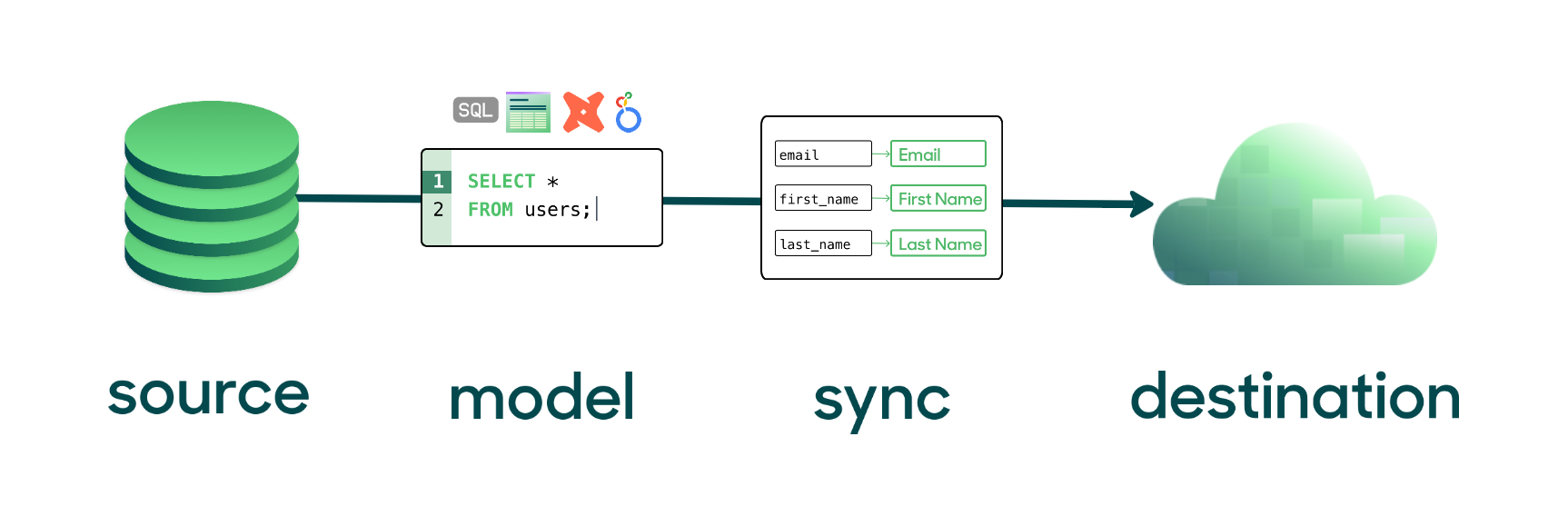
Once Hightouch knows what data model to query from a source, you can configure a sync to declare how you want that data to appear in your destination.
You can build multiple syncs to different destinations from the same model. For example, you can use a model containing customer data to configure syncs to sales, marketing, and support tools. Using the same data model ensures that all parts of your business are working off the same source of truth.
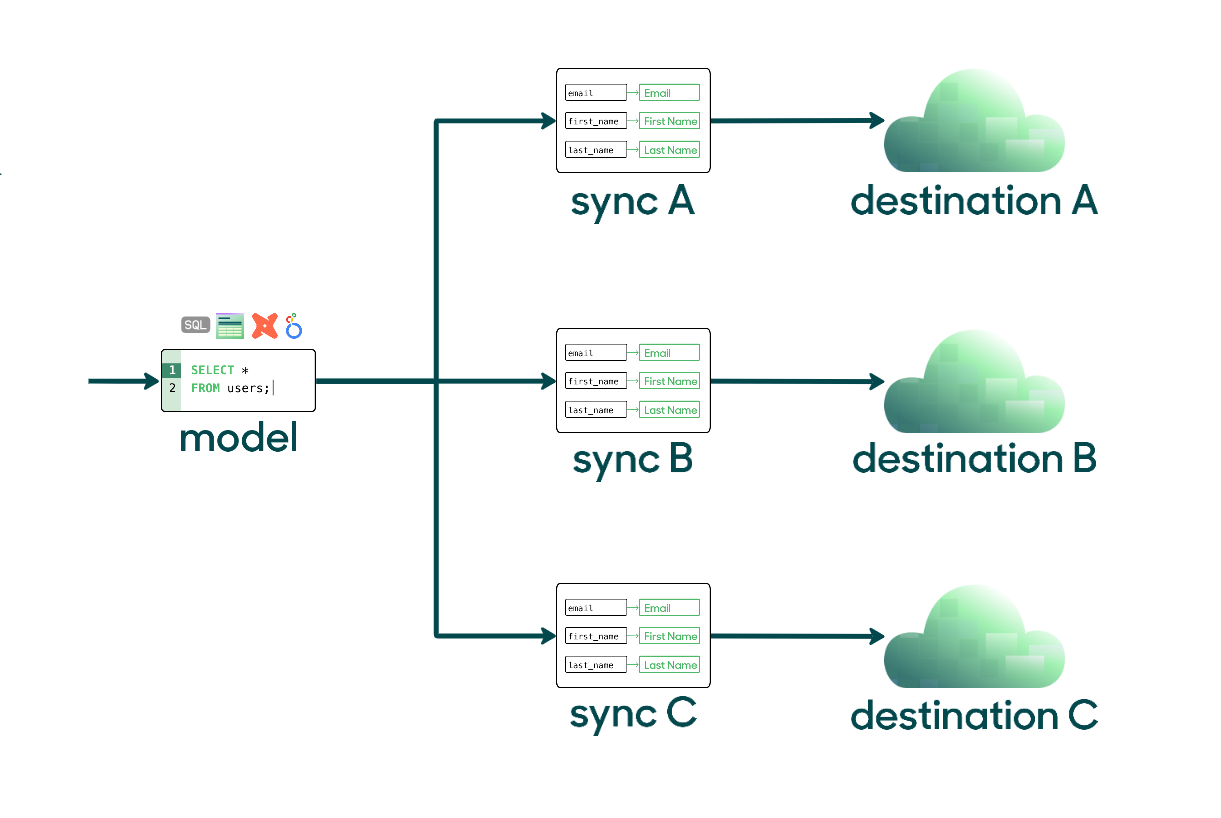
If you're syncing multiple object types to the same destination, for example, contacts and custom behavioral events to HubSpot, you must configure separate syncs for each sync type.
Sync configuration varies depending on the destination but generally includes the same steps. You select the appropriate sync mode for your use case—upsert, insert, update, etc.—and declaratively map model columns to destination fields.
Part of sync configuration is scheduling. Besides triggering syncs manually, you can schedule syncs to run on a recurring schedule. You can also trigger syncs automatically via dbt Cloud, Fivetran, Airflow, Dagster, Prefect, Mage, or the Hightouch REST API.
Refer to the sync overview page for more information on sync configuration and scheduling.
Change data capture
If Hightouch were to send all query results from a model at every sync, we'd likely be overwriting values that don't need updating. To prevent making excessive API requests and send only necessary updates to your destinations, Hightouch uses a process commonly referred to as diffing or change data capture (CDC).
How change data capture works
Whenever a new sync is triggered, Hightouch compares the previous sync run to the current set of query results. To do this, Hightouch keeps a record of the data sent in the last sync. This record is the diff file.
CDC only considers mapped model columns when creating and updating the diff file, as explained in the model configuration changes section. The only exception to this rule are custom destinations, such as the HTTP Request destination.
Hightouch refers to the diff file to identify what has changed in the source data since the last run using a model's specified primary key. These are the steps for the comparison:
- Hightouch queries the source using the defined model.
- Hightouch compares all the primary keys in the query results with the primary keys in the diff file.
- For each primary key:
- If it's in the most recent query results but not in the diff file, Hightouch treats this as a new record.
- If it's in both, Hightouch scans columns for changes.
- If the primary key is in the diff file but missing from the most recent query results, Hightouch treats this as a deleted record.
- Hightouch creates a new diff file for the next comparison.
- Hightouch syncs changes, including any failed rows from the previous sync, to the destination.
In insert mode, Hightouch only syncs rows whose primary key wasn't present in the previous sync run. Ensure the selected primary key is truly unique so your destinations receive the desired data.
All and archive modes don't perform change data capture and don't store requests in the Live Debugger.
Difference-based change data capture
Hightouch uses a CDC method called difference-based CDC because it involves a full before and after comparison. Difference-based CDC is only one CDC method. This CDC method is necessary when syncing data from data warehouses since they can't produce CDC logs on arbitrary SQL queries or dbt models.
Online transactional processing (OLTP) databases like Postgres, MySQL, or Microsoft SQL Server natively log incremental changes that occur on data tables. Most modern ETL tools use these transaction logs to track changes when sending data to data warehouses or lakes. Since Hightouch does the reverse—sending data from warehouses to other destinations—it can't rely on log-based CDC. How CDC happens is a crucial difference between ETL and reverse ETL.
When change data capture occurs
Hightouch performs change data capture after receiving the query results from a source and before sending data to your destination. When a new sync is triggered, you may see the sync status is Querying. This status means the sync is in one of these three states:
- Hightouch is waiting for query results from the source
- Hightouch is saving the diff file
- Hightouch is performing the change data capture computation
Where change data capture occurs
By default, Hightouch computes CDC and stores the diff file on a Hightouch-managed infrastructure. If you're on a Business tier plan, you can configure Hightouch to use your own S3 or GCP bucket, so data is never stored in Hightouch's infrastructure.
For some sources, you can choose to do the CDC computation in your own warehouse. Using your warehouse has the advantage of faster syncs at higher volumes but requires granting write access to a separate Hightouch-managed schema in your warehouse. See the Lightning sync engine documentation to learn more.
FAQ
What happens if I change my model configuration?
As a general rule of thumb, changes in model configuration only matter for diffing purposes if they include columns used in syncs. For example, if your model queries twenty columns from a source, but only five columns are mapped to destination fields, then Hightouch will track those five columns and ignore the other fifteen. However, there is a notable exception: custom destinations, such as HTTP Request, perform diffing on all columns, even those not used in the sync configuration.
If you change a column's data type in a model—for example, changing it from a string to a number—Hightouch detects these as row changes during the next sync.
As explained in the primary key updates section, if you alter a model's primary key by selecting a different column, you will be prompted to reset the change data capture for all syncs that depend on that model. Be careful when modifying primary keys. If you keep the same column name but alter the way its values are calculated, some records may be added or deleted in your destination, depending on how your sync is configured.
Learn more about changes to your model configuration in the model column changes section.
What happens if I change my sync configuration?
If you change your sync configuration's mappings, Hightouch reprocesses the entire model query result set during the next sync run. More information can be found in the Field mapping updates section.
Does Hightouch keep historical records of change data capture?
Hightouch doesn't maintain a historical record of previous diff files. We only maintain the most recent diff file and compare every new sync with it.