The Need for Speed in Reverse ETL
An overview of how we think about speed, covering ways our customers power timely business workflows, the typical speeds they experience and improvements we are making to speed up Reverse ETL for everyone.

Pedram Navid

Zack Khan
December 1, 2021
8 minutes

Why Speed Matters for Reverse ETL
At Hightouch, we love to talk about the power of the data warehouse and using your warehouse to power operational/business workflows.
But in order to do that, you need speed. Your customers and internal stakeholders need their experiences to be fast, whether that is receiving a timely lifecycle email or having fresh data in their CRM to make a decision. As you use Reverse ETL to power more mission-critical workflows, speed is crucial.
In this article, we'll discuss ways our customers are using Hightouch to power timely business workflows, the typical speeds at which our customers are syncing data and improvements we are making to speed up Reverse ETL for everyone.
Reverse ETL Use Cases Where Speed Matters
Let's start by discussing a few live examples from our customers where speed is crucial for their business.
Vendr: Automated customer interactions powered by the data warehouse
Vendr helps companies easily manage and negotiate their SaaS contracts transparently in a centralized platform. Given how time-sensitive SaaS contracts are (with deadlines and overage fees), Vendr needs to ensure buyers fill their forms as soon as possible. To enable this, Vendr syncs product usage data to HubSpot with Hightouch, which is then used to trigger specific emails to buyers and sellers notifying them of actions they need to take to close a deal. If those reminder emails aren't effective, Vendr uses Hightouch to sync product data to Slack and automatically ping customers in their shared Slack channels as well.
Compare Club: Sending purchase events to Ad Networks for lookalike targeting
Compare Club's marketing team realized that their cost per lead (CPL) had increased drastically on Facebook as a result of Apple’s IDFA change. To help train Facebook's algorithm to target high-value customers, they needed to send purchase data as soon as customers took action within their product. They used Hightouch to sync a custom audience of customers who purchased over $5000 to Facebook for lookalike targeting that brought their cost per lead down while increasing their revenue per lead.
We got to the point where we started identifying really useful information and creating exceptional data models in Snowflake, but we wanted to activate this information in real-time across our different business teams and that is where we saw a gap in our tech stack (that Hightouch solved) - Ryan Newsome, Head of Data & Analytics at Compare Club
The Speed of a Typical Hightouch Sync
We've seen two great examples of customers leveraging the speed of Hightouch to power their use cases, but we measure speed internally across a variety of dimensions. Here's the inside scoop on how Hightouch thinks about sync speed.
One of the key metrics we have internally is the length of time it takes for a particular sync run to complete: this includes everything from when we pull the data from your warehouse until every single new or changed row is written to your destination.
One simple view is the number of syncs that complete within 30 seconds and within 3 minutes. Our current rate is 90% completing within 30 seconds and 98% within 3 minutes. While this number seems great on the surface, we love to dig deeper.
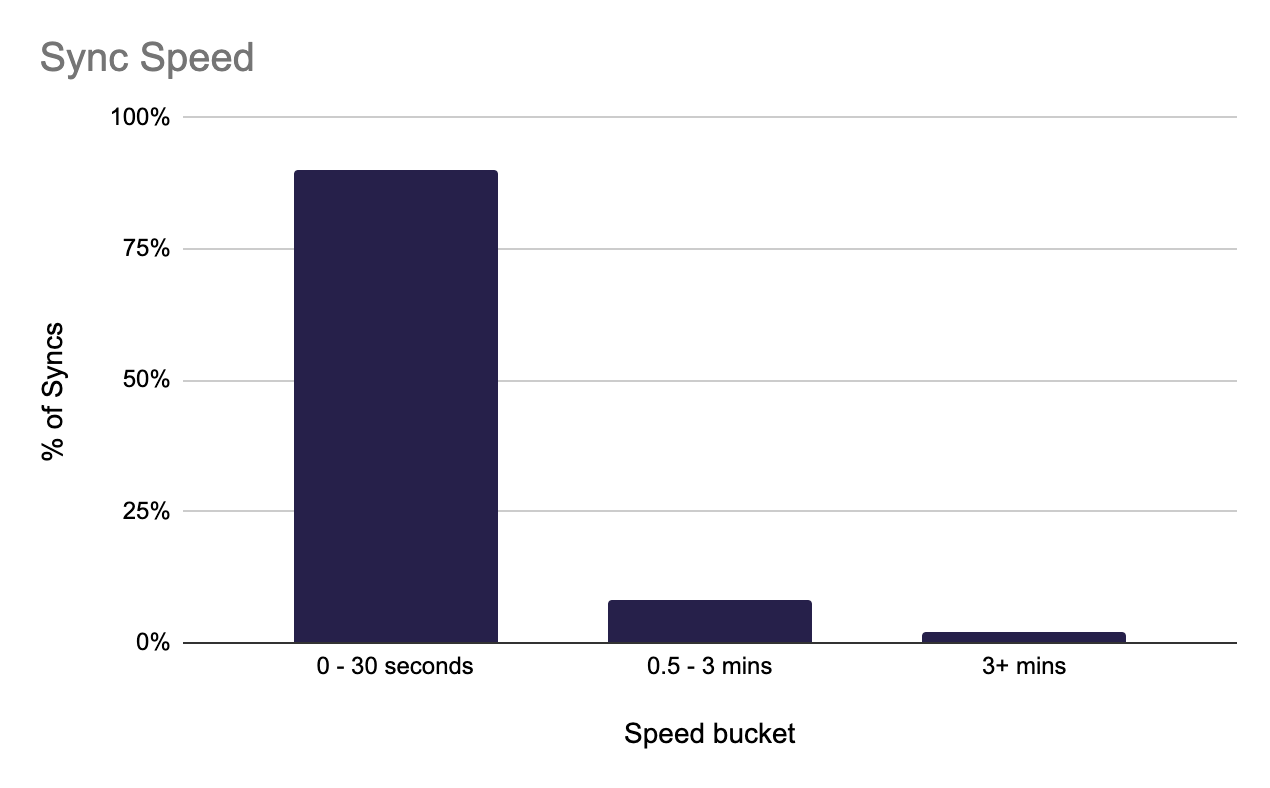
We also have targets for reducing the 95th percentile sync-speed: that is, the speed by which 95% of all sync runs complete. Since customers have different volumes of data, we normalize this by looking at seconds per operation. Said differently, how quickly do 95% of all rows take to write to the destination? We've reduced this number by 50% over the last 3 months to just fractions of a second per operation, but are always looking to tune it further.
The last way we can break this metric down is by destination. Not all destinations are created equal, some have limited APIs, limits to the number of records per batch, some customers are on different plans which necessitate different rate-limits, plus new features and APIs are being released by our many integrations. As a result, we break down our 95th percentile metrics by our 70+ destinations, looks for areas of improvement where we can make incremental improvements to the overall sync speed.
3 Areas of Improvements
To improve sync speed, there are three places we can focus on: improving destinations, improving sources, and wider platform enhancements.
Destinations
First, we look at our destinations. This is the most obvious source of improvements. Everything from using newer versions of APIs, fine-tuning the number of batch records, and thinking carefully about how we implement the various modes can help improve speed here.
APIs are constantly changing, and as mentioned, different customers may have different capabilities for the same destination. Some destinations limit the number of requests we can perform in a day based on the customer's pricing agreement, others may have limits on complexity and downstream impacts, such as Salesforce with Apex code. Given the wealth of possibilities, we're often working closely with our customers to help tune our destinations code to minimize the time it takes to complete a sync.
By using the data we mentioned previously, plus the tight loop of customer feedback, we're able to quickly identify problematic destinations. For example, our Mixpanel integration was slower than expected as their batch API had not been released when the destination was first created, so we quickly updated our code to use the newer Batch API, significantly increasing sync speeds by over 50x (with an average speed of 3,500 records synced per second over 2.2M records).
Sources
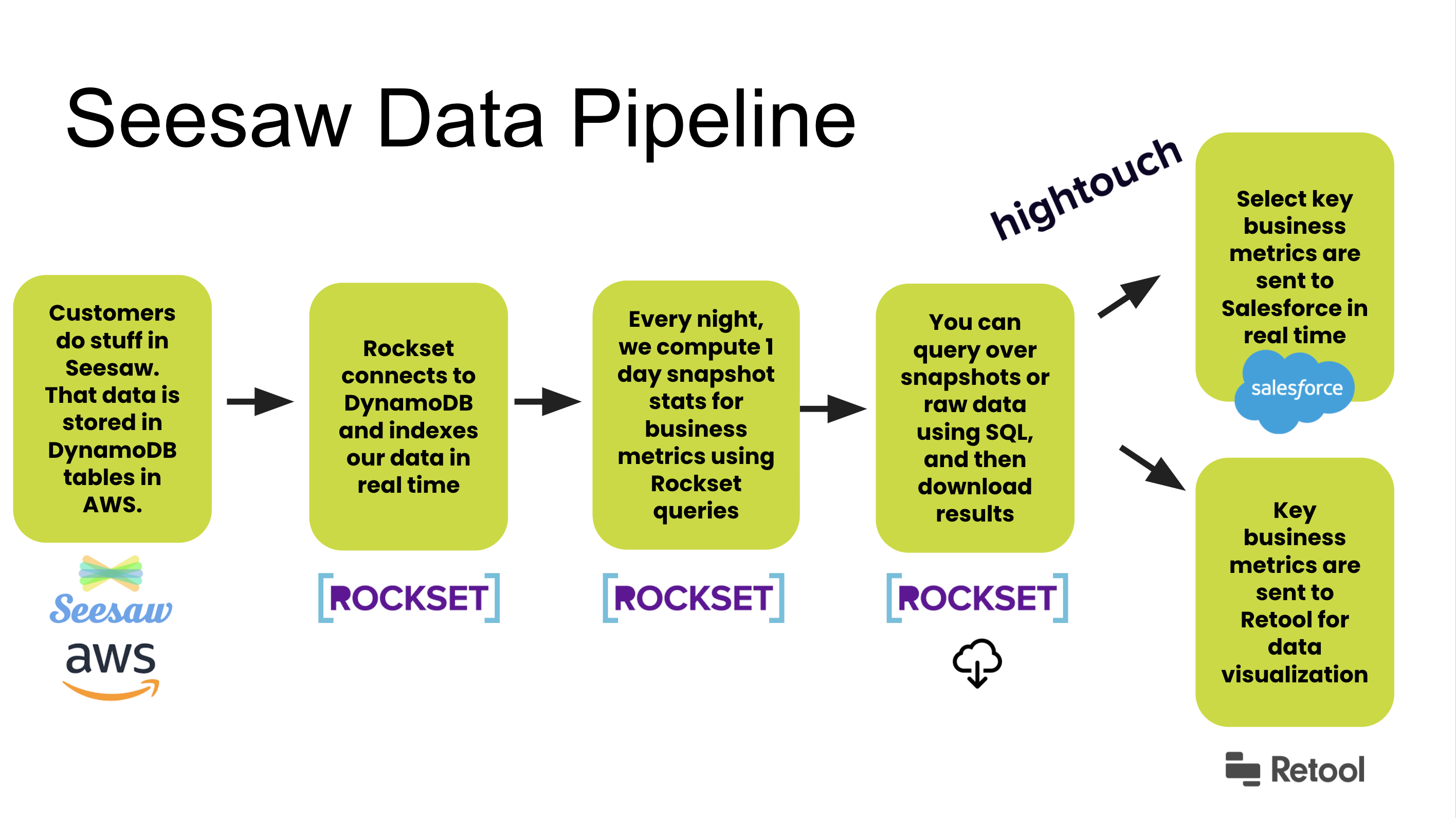
Next, we can reduce the time it takes to query a source. One way we've done this is by adding support for real-time sources and databases like RocksetDB. These sources are key for use cases where data is needed within seconds. For example, Seesaw (an e-learning platform used in 75% of US schools) syncs data from Rockset to Salesforce with Hightouch to enable their sales reps with fresh insights like how many students in a district are online at that moment. We will continue to add support for more real-time sources like Kafka and Kinesis.
Another area for improvement is how we pull data from sources, such as how we handle type conversions.
Platform
Finally, we can extract as much performance as possible out of the Hightouch platform itself. Under the hood, Hightouch records metadata about your syncs to power features like the Debugger. This record-keeping carries some overhead, so we've invested engineering effort in reducing its impact on sync performance. Our engineers have identified inefficiencies and refactored parts of our system to introduce parallelization and eliminate blocking too. We've been able to achieve as high as a 2x performance improvement in specific situations, with even more improvements coming soon.
Our Plan for Sync Speeds
Benchmarking our sync speeds is a point-in-time reference that will quickly become outdated because we're improving destinations and our platform every week. That's why our plan is to move in a direction that gives our users visibility into expected speeds and updates users as those speeds improve over time (or even if they get slower for any reason). Our plan is to build a benchmarking framework and include speeds in our docs that are constantly kept up-to-date, as we mature our platform over time. With this added transparency, we invite users to suggest ideas that help us improve our speed too! If you see Hightouch syncing data slower than you would expect based on the API rate limit, let us know, we love when customers help us improve!
While we continue to improve on sync speeds, we want to be clear that they are just one of many product improvements our engineering team is working on. We're focused on delivering value across the entire set of features Hightouch has to offer. There’s a point of diminishing returns with fine-tuning speeds, so we like to make improvements where they can enable customers to accomplish new things. Our focus is largely driven by our customers: if we’re delivering value for them, then we know we’re working on the right projects.
That’s why we look to more than just sync speeds. Features like git and dbt integrations, more integrations with SaaS tools, our live debugger, the ability to test a row before sending a full sync, lineage, and more are all driven by feedback from our amazing customers.
We hope this has been a useful primer on how we think about sync speeds internally at Hightouch. If there’s any other topic you’d like us to discuss, or you have feedback on where we should focus to deliver more value for you as a customer, let us know. We’d love to hear from you.