The future of data integration: what iPaaS & Workflow Automation tools got wrong
Learn about the shortcomings of iPaaS/Workflow Automation solutions and why the future of data integration is declarative

Tejas Manohar

Luke Kline
September 21, 2021
11 minutes

The future of data integration: what iPaaS & Workflow Automation tools got wrong
In 2021, the average company uses an average of 100 SaaS applications. For the most part, this is great news because it means companies are spending far less time on undifferentiated work and more time on the unique parts of their business.
That said, there’s one problem - with the adoption of each SaaS application, a new data silo is created. Salesforce knows about your sales pipeline, Zendesk knows about your support tickets, and Iterable knows about your lifecycle marketing campaigns. The list goes on…
With this abundance of data silos, everyone in your company has a limited view of your customer, hurting sales and damaging the customer experience. There are a number of platforms aimed at solving these data silos. We wrote about this previously in our blog post on the data integration landscape. But, when anyone mentions integrating data into SaaS tools, there’s a clear elephant in the room - iPaaS or Integration Platforms-as-a-Service solutions like Mulesoft, Celigo, Dell Boomi, Tray.io, and Workato.
Despite the popularity of iPaaS Solutions and multiple unicorn exits in the space including Salesforce acquiring Mulesoft for $7B, I’d make the argument that data integration is still broken and fundamentally, iPaaS is the wrong solution. In this post, I’ll discuss where iPaaS solutions went wrong, and why the future of data integration is declarative.
What is an iPaaS solution?
iPaaS solutions are either low code or no-code software platforms that enable companies to connect various applications together via their APIs without managing servers, writing complex code, etc. The idea is to allow companies to integrate different applications together without needing software engineers.
My favorite iPaaS solution is Zapier. If you haven’t used it before, Zapier basically allows you to connect apps together through a series of triggers and actions.
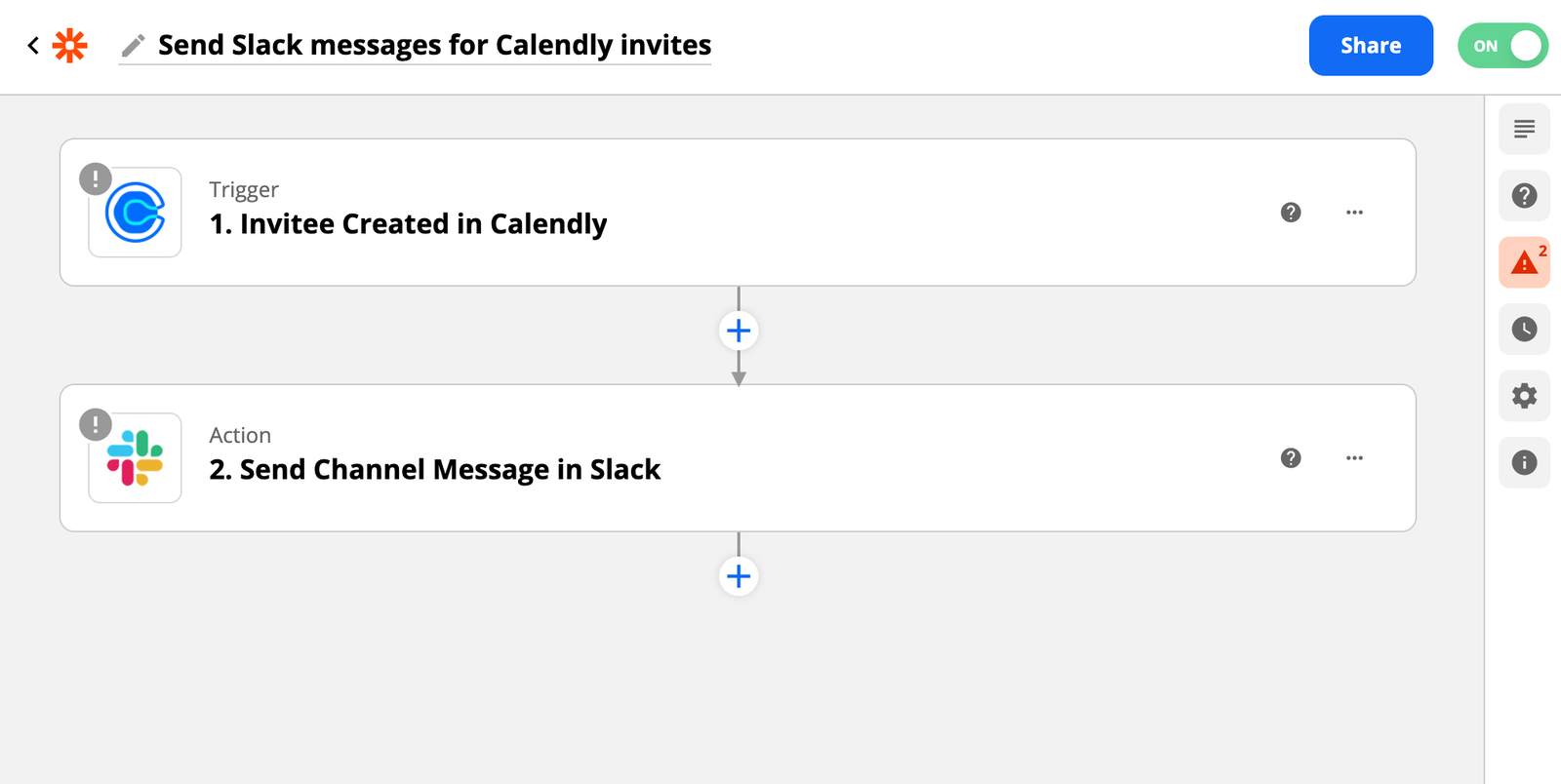
The screenshot above shows a real “Zap” (or Zapier workflow) we use internally at Hightouch. Every time a new event is created in Calendly, it sends a message to one of our Slack channels.
This is a great use case for iPaaS solutions, but it’s also a pretty simple workflow. What happens when the use cases become more complex?
Zapier is a great product, but it doesn’t lend itself to more complex workflows. In a talk that I watched years go, Zapier’s cofounder/CTO described this as intentional. Their user testing showed that as soon as you added common programming functionality like if/else branches, loops, and variables, you greatly increase the bar for who can use the product.
Fortunately (or maybe unfortunately?), there are alternative iPaaS solutions that focus on more complex workflows. A popular example is Tray.io. Ironically, we actually used Tray.io at Segment, another player in the data integration landscape that I helped scale before founding Hightouch.
Let’s dive into an example!
Real example of using an iPaaS solution (tray.io)
Tray has a popular step-by-step walkthrough on how to use their product to integrate your Stripe subscription data with Salesforce contracts. At a high level, the Tray workflow periodically checks Salesforce for contracts that don’t have an associated Stripe subscription and updates them.
Sounds simple, right? You tell me!
Here's the final result:
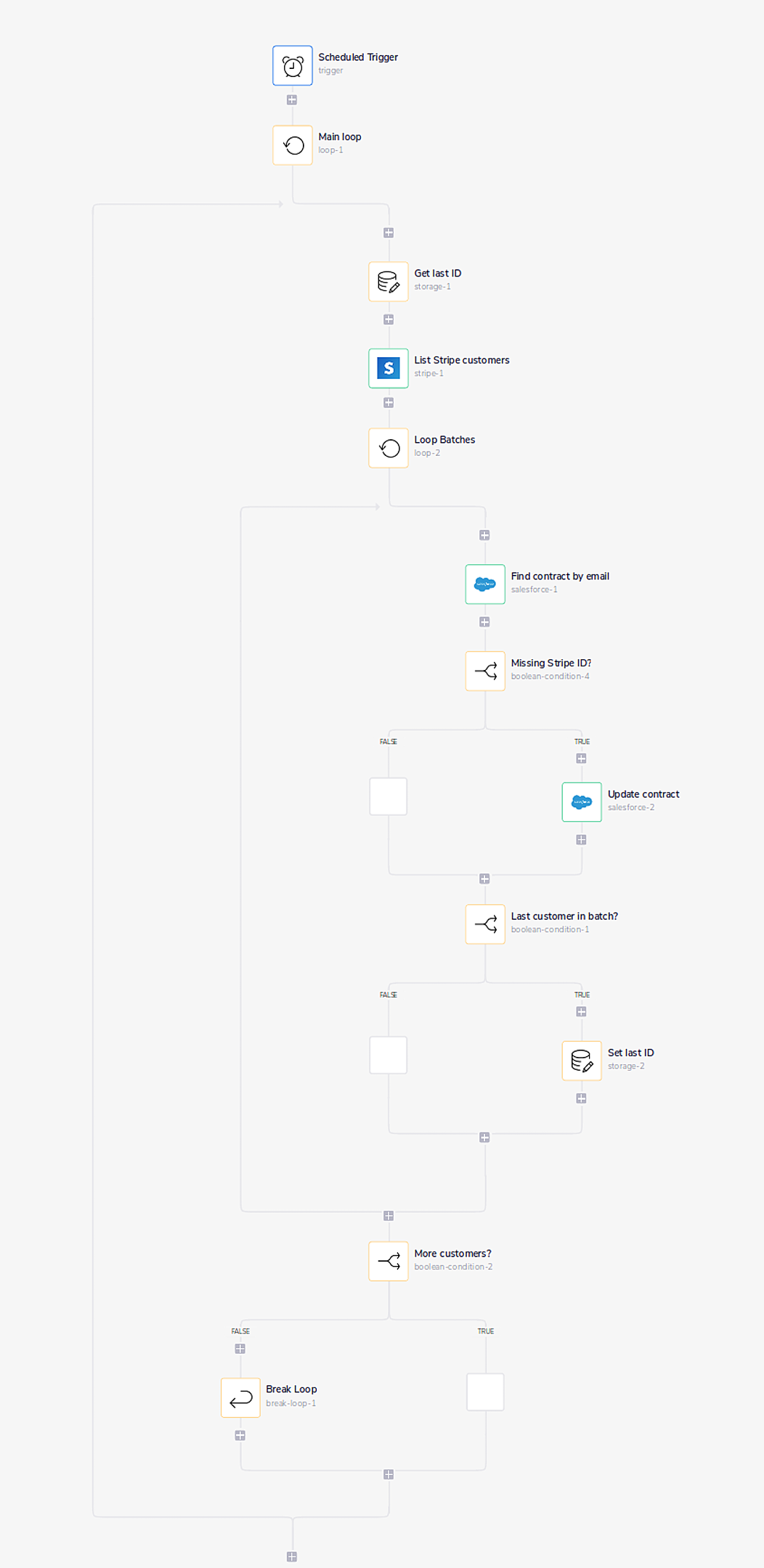
That’s a lot of steps! And, the above screenshot doesn’t even tell the full story. Almost every one of these steps has a bunch of complexity within them that all depend on each other in obtuse ways.
If you’re curious to understand what each step in the above Tray workflow does (warning: it’s a lot!), read the section below.
Breaking down a "simple" iPaaS workflow (Optional)
1: The first step schedules the workflow to run on an interval, e.g. every hour, day, week, etc.
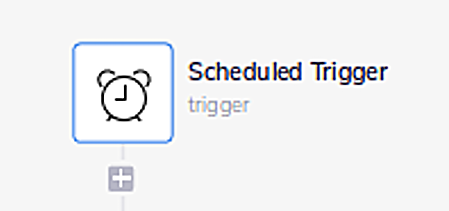
2: The second step declares a “loop”. Stripe’s API can only return so many accounts per API call so you have to keep calling the API until you’ve read all the accounts. This is called “pagination”.

3: Every time the main loop runs, ask Tray.io for “the last Stripe customer ID” that you left off at and use that to ask Stripe’s API for the next set of customers

4: Create another “loop” over the subset of Stripe customers returned and search Salesforce for a contract with the same email address.
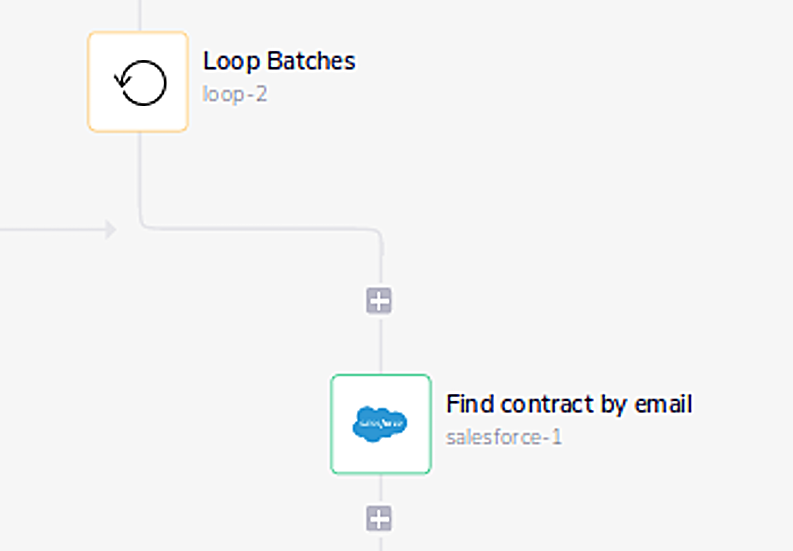
5: If a Salesforce contract is found and is missing a Stripe ID, update the contract in Salesforce. If the Salesforce contract already has a Stripe ID, do nothing.
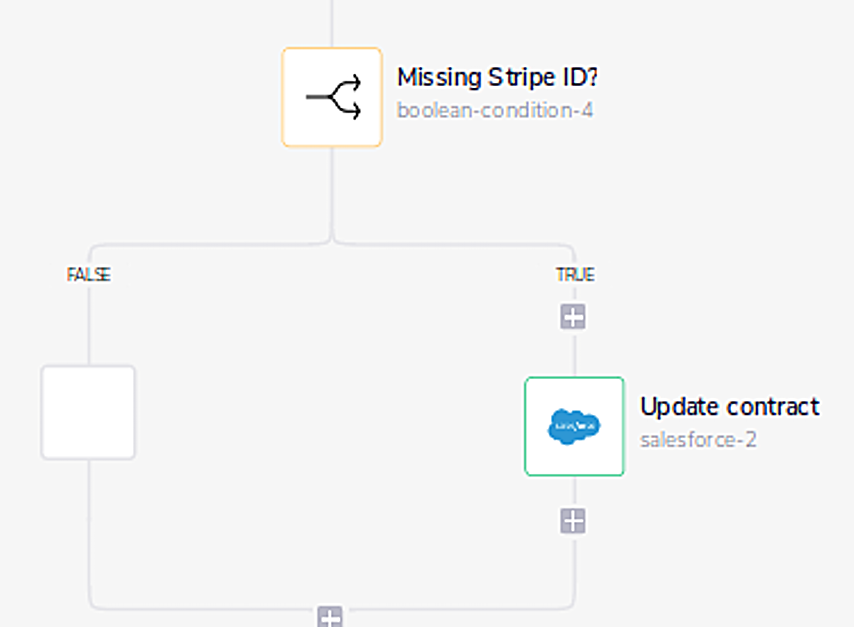
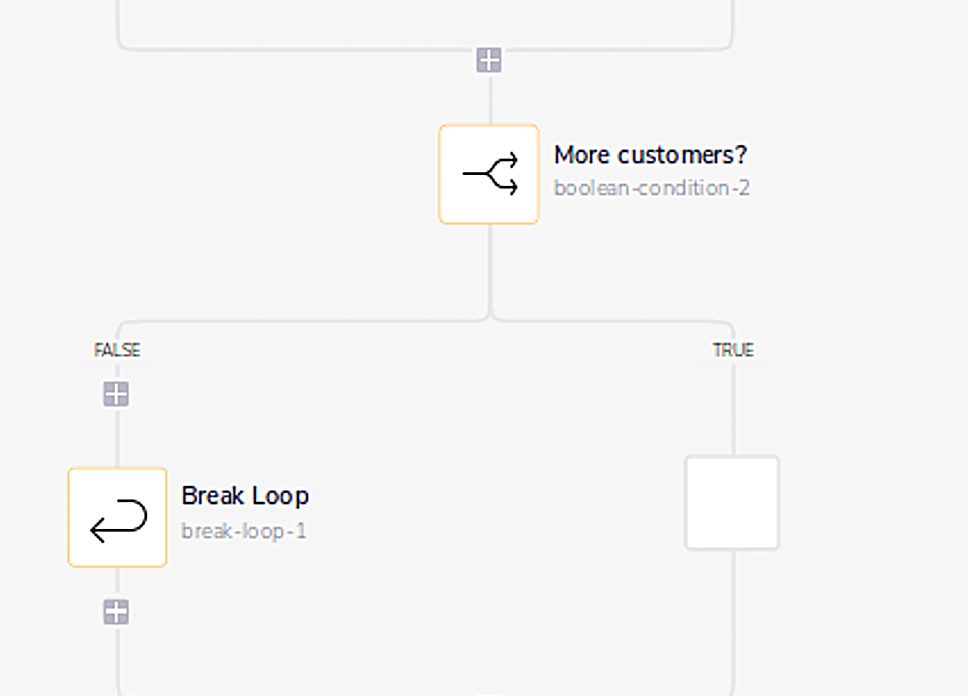
6: The rest of the Tray workflow actually has little to do with Salesforce or Stripe— more to do with Tray. Once you reach the last Stripe customer in the batch, ask Tray to store the last Stripe customer ID so that when the main loop runs again, you know where you left off. If you don’t have a computer science degree, you might already be lost here.

7: If Stripe’s API says you’ve read all the customers, you “end” the Tray loop. Without this, you would be continuously calling the Stripe API and eating up all of your API calls in the process!
An easier way to connect data
So, we know this is complicated, but so is coding! Can it really get much easier? The answer is yes. Before I dive into why I’d imagine you want some proof.
Using a Reverse ETL tool like Hightouch, this workflow would just be a SQL query:

And some settings:
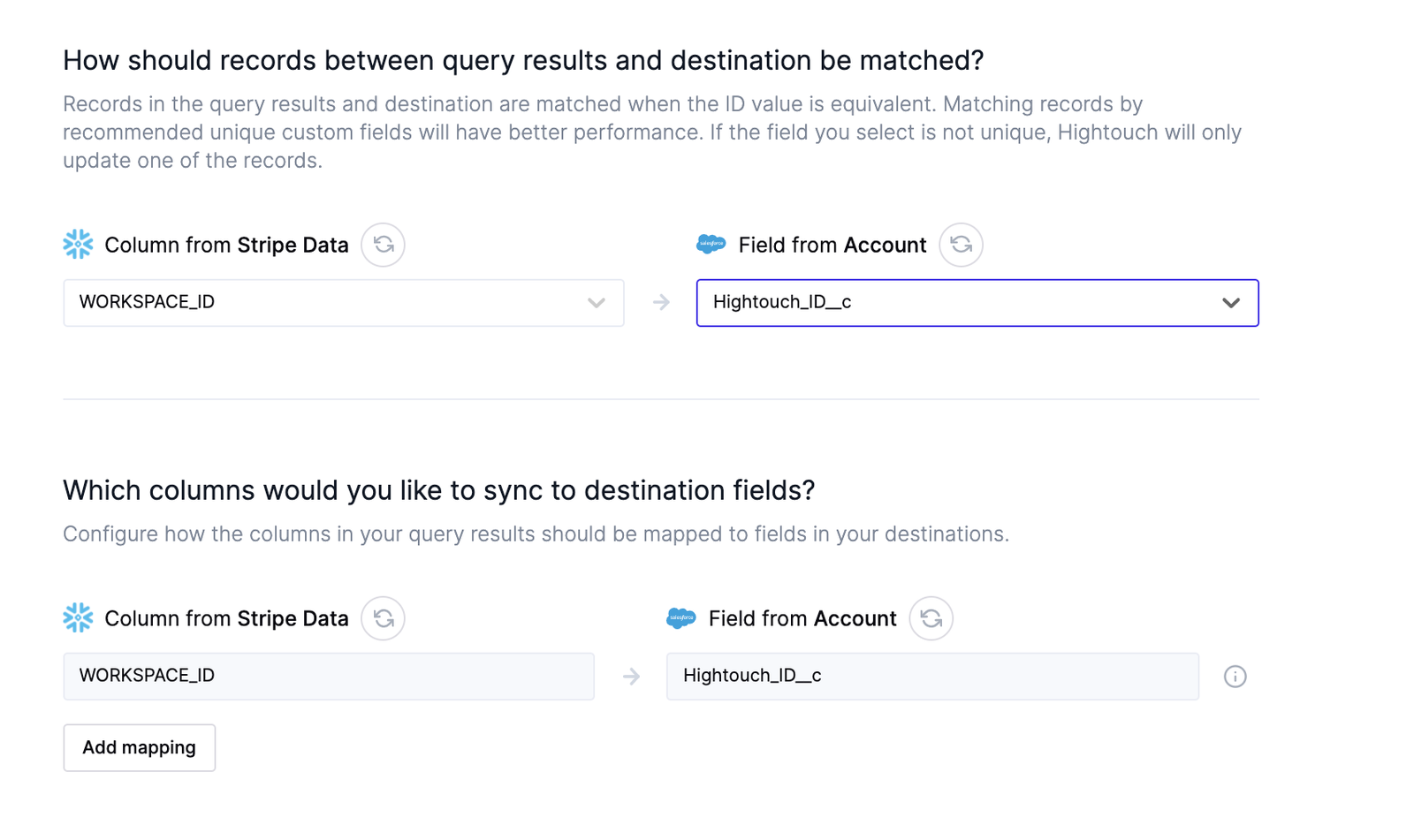
But, this isn’t meant to be an advertisement. Let’s dive into why declarative solutions like Hightouch are so much simpler, or in other words, what iPaaS got wrong.
What iPaaS solutions got wrong?
Overall, the premise behind iPaaS solutions is solid. They are very powerful for business workflows. However, they are not built to handle core customer data use cases. All iPaaS solutions basically just perform actions when a specific trigger is met. This is why I firmly believe that iPaaS solutions have three core problems:
iPaaS solutions are imperative.
You have to tell them exactly what to do and how to do it; and if you don’t know how to do it yourself, good luck teaching a solution like Tray to do it. In the example above using Tray.io where I walked through the process of integrating Stripe purchasing data with contracts in Salesforce there are a ton of different steps required to make this happen.
Depending on the data that you are looking to move and the complexity of your business, this can get extremely time-consuming and complicated very fast. A good way to think of this is through the lens of a GPS system. Today these are built innately within every smartphone. Before GPS systems existed, the easiest way to get from point A to point B was to draw out a map highlighting the route to your end destination (ex: turn left on Smith Street and turn right at exit ABC. Today, all you have to do is input your end destination and follow the blue line on your smartphone. iPaaS solutions do the exact opposite, they require you to do a ton of work on the back end. Every single time you add a new data source, you have to create another complicated workflow.
Data integration should be declarative. You should only have to tell the tool your end goal; you shouldn’t have to account for everything in the middle.
iPaaS solutions are point-to-point.
These solutions simply move your data from point A to point B or the inverse of that. It’s nearly impossible to combine data sources to generate a 360-degree view of your customers without creating a complex and convoluted mess of workflows that are extremely fragile and prone to failure. This means that you can’t associate information like product usage data from tool like Amplitude and combine marketing data from a tool like Marketo and then push that information into your CRM (i.e. Salesforce or Hubspot). Additionally, you wouldn’t be able to send information like ARR (annual recurring revenue). You would have to send something simple like individual purchases, order data, etc. This poses a real problem because it means that everyone in your organization will have a slightly different view on the customer and this translates into an inconsistent customer experience.
iPaaS solutions are not accessible.
iPaaS solutions create an illusion of accessibility with their visual UIs. In reality, most of them have a steep learning curve, because a substantial amount of coding is required to create the end result that you are looking for. For instance, Tray has a live monthly training session because it is so complex. Some of these solutions come with ready made templates but these are often unusable because every business is unique. Likewise, iPaaS solutions are also extremely rigid. Simple things like matching accounts based on email addresses are inaccessible. In addition, the intricate details behind the workflows and the code are often tied to the person who created them, so if that employee leaves, you will be stuck picking up the pieces he left behind.
A Look Ahead: Declarative Data Syncing
The future of data integration should be declarative. You shouldn’t have to worry about anything that goes on in the backend. Instead, you should be thinking about the end goal that you are looking to achieve.
Modern data integrations solutions solve all of these problems as a native SaaS solution. For example, Reverse ETL platforms like Hightouch allow you to send data from your warehouse to any SaaS tool in 3 easy steps:
Define the data you want in your preferred style: You can expose a whole table with our table selector, use our visual audience builder to define your data in our point-and-click UI, define your data in SQL or with an existing dbt model.
Next, choose your end destination tool (ex: Salesforce) and map the fields in your data to fields in your destination tool that you want to update.
Lastly, schedule how frequently you want your data to sync by scheduling it on a set interval (ex: every minute or hour), via API call or doing it manually yourself.
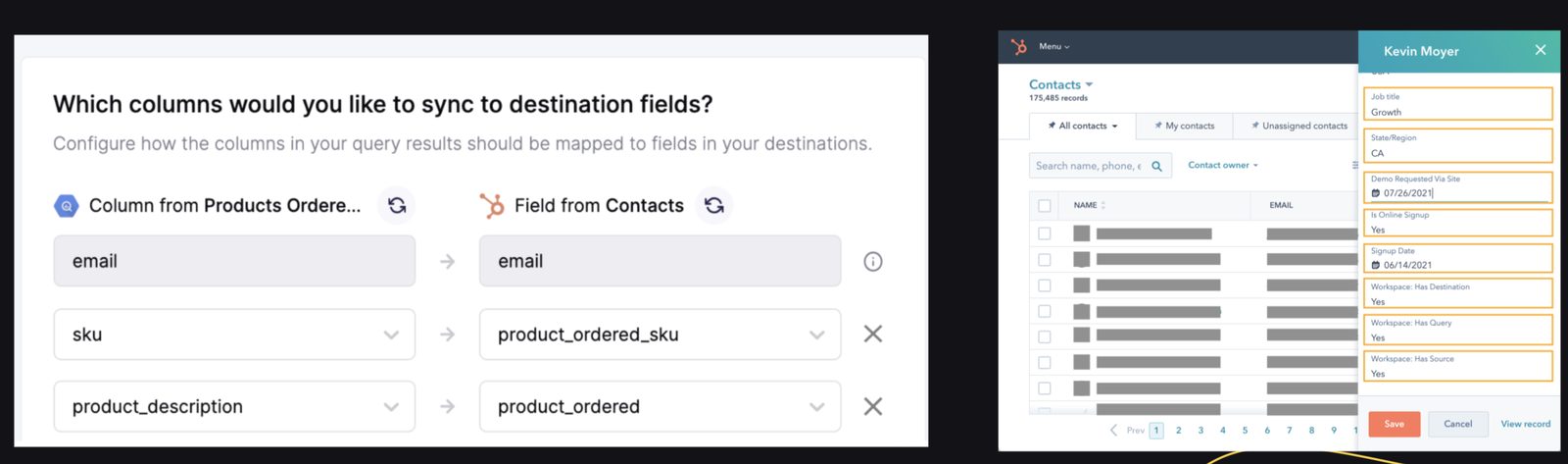
The beauty of this declarative approach is that everything else is handled for you. With iPaaS, you need to worry about painfully common "edge cases" like foreign keys, API limits, and more that lead to a nasty tree of if/else statements
Why is this method better?
Declarative data integration is superior to imperative data integration for many reasons, the main of which being that it addresses all the edge cases so you don’t have to. For instance, conventional iPaaS tools only allow you to match rows based on specific ID’s (ex: SalesforceID or HubspotID). With Hightouch, you can match rows by matching fields of your choosing. Likewise, iPaaS solutions send all your data each time, pulling more data than is needed and potentially adding to your bill if your destination tool is charging per API call. Hightouch is able to diff the results between your syncs, enabling you to only send the rows that changed. This saves you a huge amount of time and money. In addition, iPaaS solutions often run into API rate limits. With Hightouch, if any of your rows get rate limited, they will automatically be retried later so that your entire sync does not fail. Hightouch also stores logs in our live debugger, so that you can quickly identify and fix errors. All of this is done for you, without you even having to think about it. You just have to choose which data source and which destination you want to sync your data to.
Data integration is a problem that is not going away anytime soon. In fact, it will most likely become more challenging as the data ecosystem expands, but since companies can choose from the “best of breed” solutions, the products will continue to improve for everyone. At the end of the day, every business is different and every employee has a specific role they were hired for. The question you have to ask, is what could be enabled if data integration was not a blocker for your various teams?