Exploring Data Lineage with OpenLineage
In this post, we ask what is data lineage and take a detailed dive into OpenLineage and how it aims to unify metadata and lineage across tools to make data lineage easier to reason about.

Pedram Navid
June 11, 2021
7 minutes
With the ever-expanding ecosystem around data analytics, we've started to see an increase in interest around metadata and data lineage but it's not always clear what data lineage is and why it is useful. We've seen companies like Monte Carlo Data and Datakin emerge to help address some of these issues, with a focus on increasing data observability. We are also seeing tooling expose valuable metadata that can help trace data lineage, dependencies, and pipeline health.
However, while the modern data stack is highly interoperable, there is still a lack of cohesion when it comes to metadata and lineage data. OpenLineage is an emerging standard that helps to bridge the gap across these various tools when it comes to metadata.
What is Data Lineage?
Data Lineage describes the flow of data to and from various systems that ingest, transform and load it. Many data tools already have some concept of data lineage built in, whether it's Airflow's DAGs or dbt's graph of models, the lineage of data within a system is well understood. The problem is that there are a multitude of systems and understanding the graph of the movement of data across systems is much more difficult.
This immediately becomes apparent when a bug is found somewhere downstream and analysts need to search backwards through code across tools to identify why something broke. Even more mundane tasks like identifying which teams are consuming data from a field that is about to be deprecated for regulatory reasons can be an impossible task without a good understanding of data lineage.
What is OpenLineage?
OpenLineage is an open standard for metadata and lineage collection. It is supported with contributions from major projects such as pandas, Spark, dbt, Airflow, and Great Expectations.
The goal is to have a unified schema for describing metadata and data lineage across tools to make data lineage collection and analysis easier.
The standard defines some key concepts, such as a Job, Run, and Datasets while allowing for flexibility for each provider to add additional metadata using facets.
The standard is formalized as a JsonSchema which makes it easy to work with and validate. The Github repo comes with two clients in both Java and Python but the standard is simple enough that writing a client in any language should be fairly straightforward.
What this ends up looking in practice is a series of JSON-formatted events, like so:
[{
eventType: 'START',
eventTime: '2021-06-09T08:45:00.395+00:00',
run: { runId: '2821819' },
job: {
namespace: 'hightouch://my-workspace',
name: 'hightouch://my-workspace/sync/123'
},
inputs: [
{
namespace: 'snowflake://abc1234',
name: 'snowflake://abc1234/my_source_table'
}
],
outputs: [
{
namespace: 'salesforce://mysf_instance.salesforce.com',
name: 'accounts'
}
],
producer: 'hightouch-event-producer-v.0.0.1'
},
{
eventType: 'COMPLETE',
eventTime: '2021-06-09T08:45:30.519+00:00',
run: { runId: '2821819' },
job: {
namespace: 'hightouch://my-workspace',
name: 'hightouch://my-workspace/sync/123'
},
inputs: (same as above)...
producer: 'hightouch-event-producer-v.0.0.1'
}]
Before we dive into the details of what these fields mean in OpenLineage, let's take a look at some of the questions we may wish to answer with lineage data.
What is Metadata and Why Is It Useful?
Metadata is data about data. Within the Modern Data Stack, there are a variety of tools that move and transform data as it goes from source to destination. This adds a web of complexity that makes it hard to reason about. Tools like dbt expose the lineage of data as it works through the warehouse through their documentation as well as with exposures. Airflow also exposes its DAG for analysis through an API. Further, Reverse ETL tools like Hightouch, take transformed data from the warehouse and sync it back into your end-user tools like Salesforce and HubSpot.
The question an analyst might have is why is there an error in this one particular field in my Salesforce Accounts object. Being able to trace the lineage of the data back through all the various tools and systems that manipulated and updated it is crucial in being able to understand why a certain field has a certain value.
Beyond debugging errors, lineage data also aids in data discoverability. As companies grow, teams lose insight into the various upstream and downstream systems their data relies on. Being able to understand the implication of a potential breaking change could be made possible by an end-to-end data lineage system that traces the flow of data across teams and systems.
This is just the tip of the iceberg, as there are countless other use cases from analytics to meeting regulatory requirements but for now, let's get back to OpenLineage and why the approach is so interesting.
Key OpenLineage Concepts
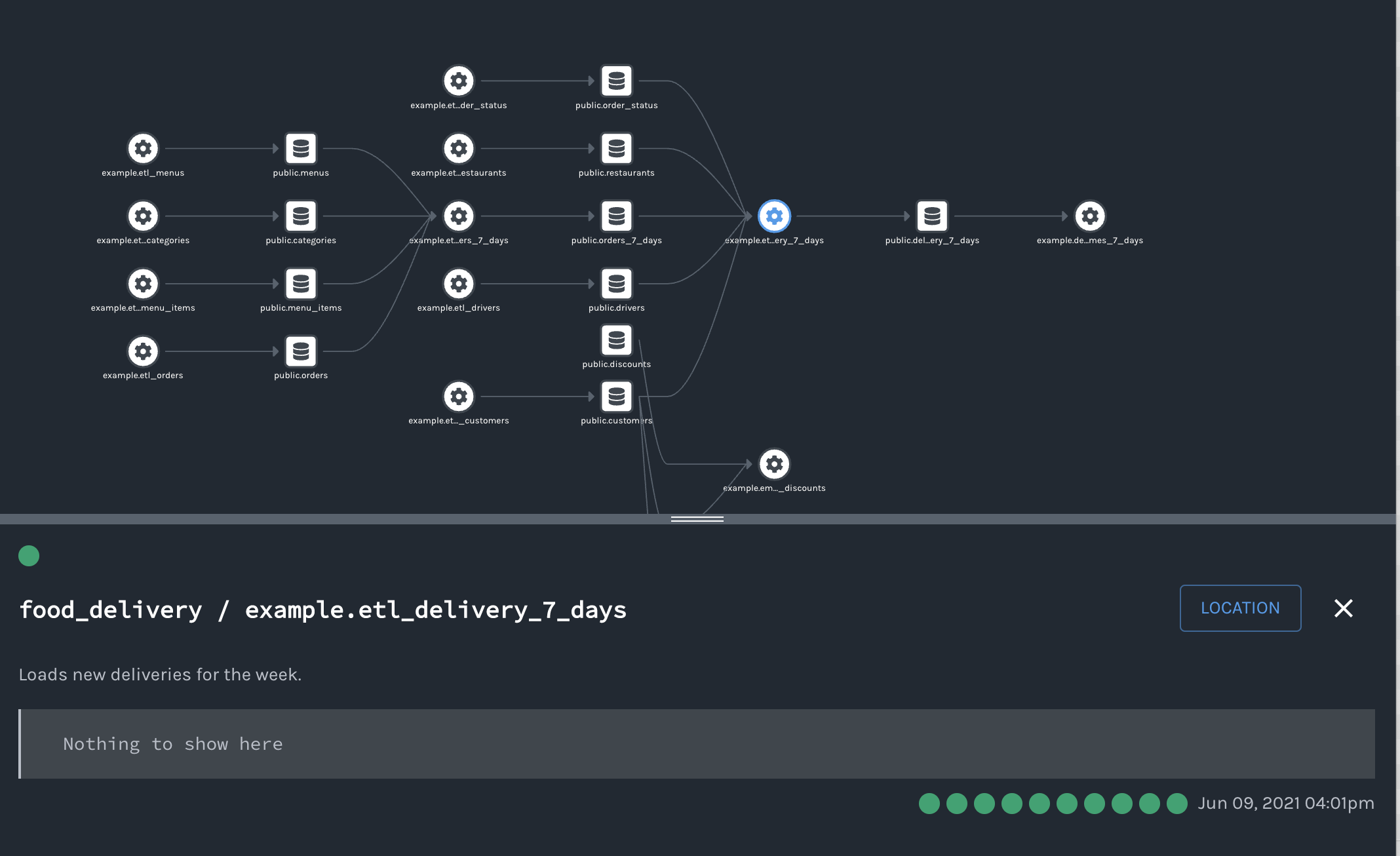
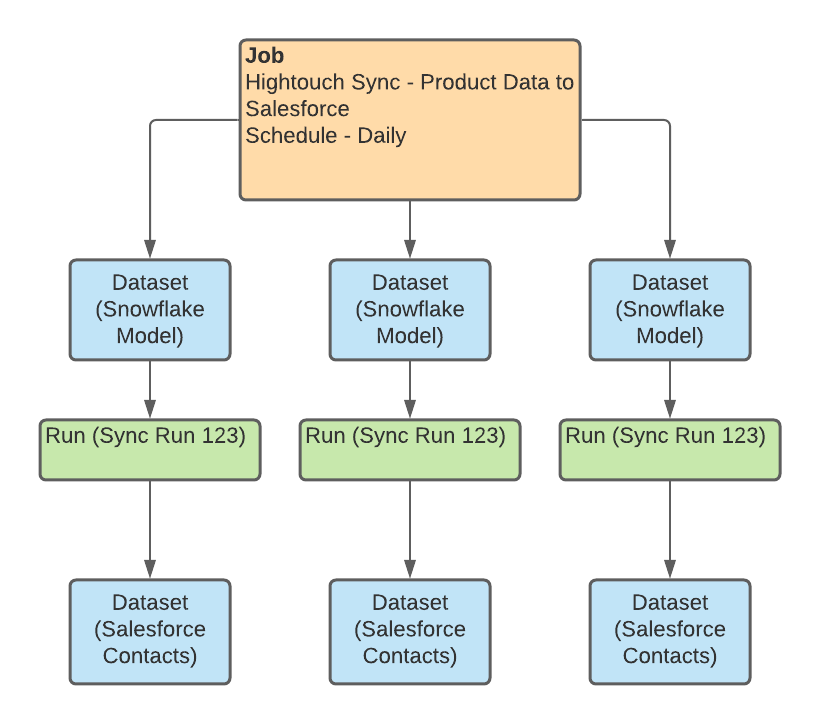
One of the main issues that OpenLineage seeks to solve is the lack of a standardized way of instrumenting jobs across various tools. The standard itself is stripped down pretty bare, to only a few key concepts: a run, a job, and a dataset which makes it easy to apply to a variety of scenarios. The usage of facets allows very flexible extendability to suit the unique needs of any one particular tool.
A job is the highest level of abstraction, and represents some type of process that consumes and produces datasets. In Airflow, this might be your DAG. In dbt, this might be the the particular model being run. At Hightouch, a sync translates nicely as a job.
A dataset is an abstract representation of data. It could refer to tables in a database, a view in a warehouse, a file in cloud storage, or even an object in your CRM.
All jobs have state. That is, they progress and change through time, every run begins with a START state and ends with a COMPLETE, ABORT, or FAIL state. These state transitions are timestamped which allows for performance analytics and helps identify potential bottlenecks.
A run is a particular instance of a job. If you think of a job a class, then the run is the particular instance of that class, with a unique identifier, that helps unite the events that represent the changes of state through time.
Finally facets are additional metadata that can be attached to either a job, dataset, or run to further describe these objects. These are completely extendable too, which makes it easy to add useful information without having to rewrite the standard. There are some built-in facets for describing the schema of the datasets, the raw SQL used to generate the dataset, and more..
Getting Started with OpenLineage
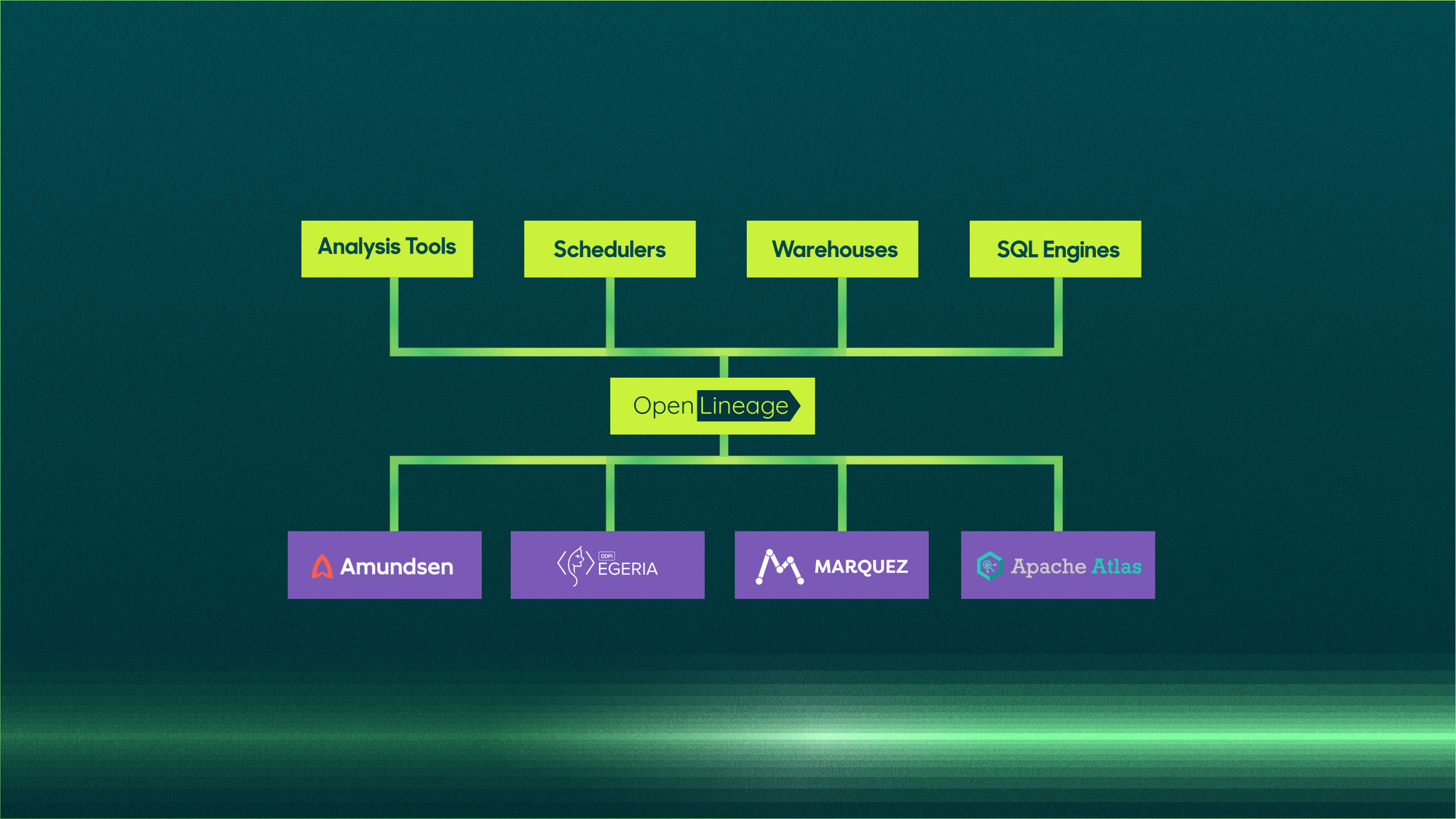
To get started with using OpenLineage, the first step is creating events. The Github repo comes with two clients for Python and Java, so these could be integrated directly into your applications that generate events. If you're looking to get started with Airflow, Marquez which is a reference implementation of OpenLineage has some code to get you started. There is also work being done to integrate with dbt, although that work is not yet complete as of this writing. Hightouch also has a beta OpenLineage implementation available for testing, where we can emit data to an endpoint through Hightouch for all our sync jobs.
OpenLineage is still in its early stages, so expect some changes as the standard gets solidified and tools begin to adopt greater support for the standard.
Going Further With OpenLineage
Once you have integrations that emit the data, the next question is what to do with them. Marquez is one potential data store, but there are many possibilities. Apache Atlas is another open-source tool centered around metadata collection. It's even possible to write the data directly to the warehouse and then perform analysis and reporting from the structured JSON objects. We're working on a dbt package that can expose just that, so let us know if you're interested in helping out with testing out the package or getting access to OpenLineage metadata.