What's the Difference Between Reverse ETL Tools and Segment?
Trying to understand the differences between Reverse ETL and Segment? Find out here! We break down the key differences between the two technologies, so you can make an informed decision.

Zack Khan

Tejas Manohar
June 4, 2021
8 minutes
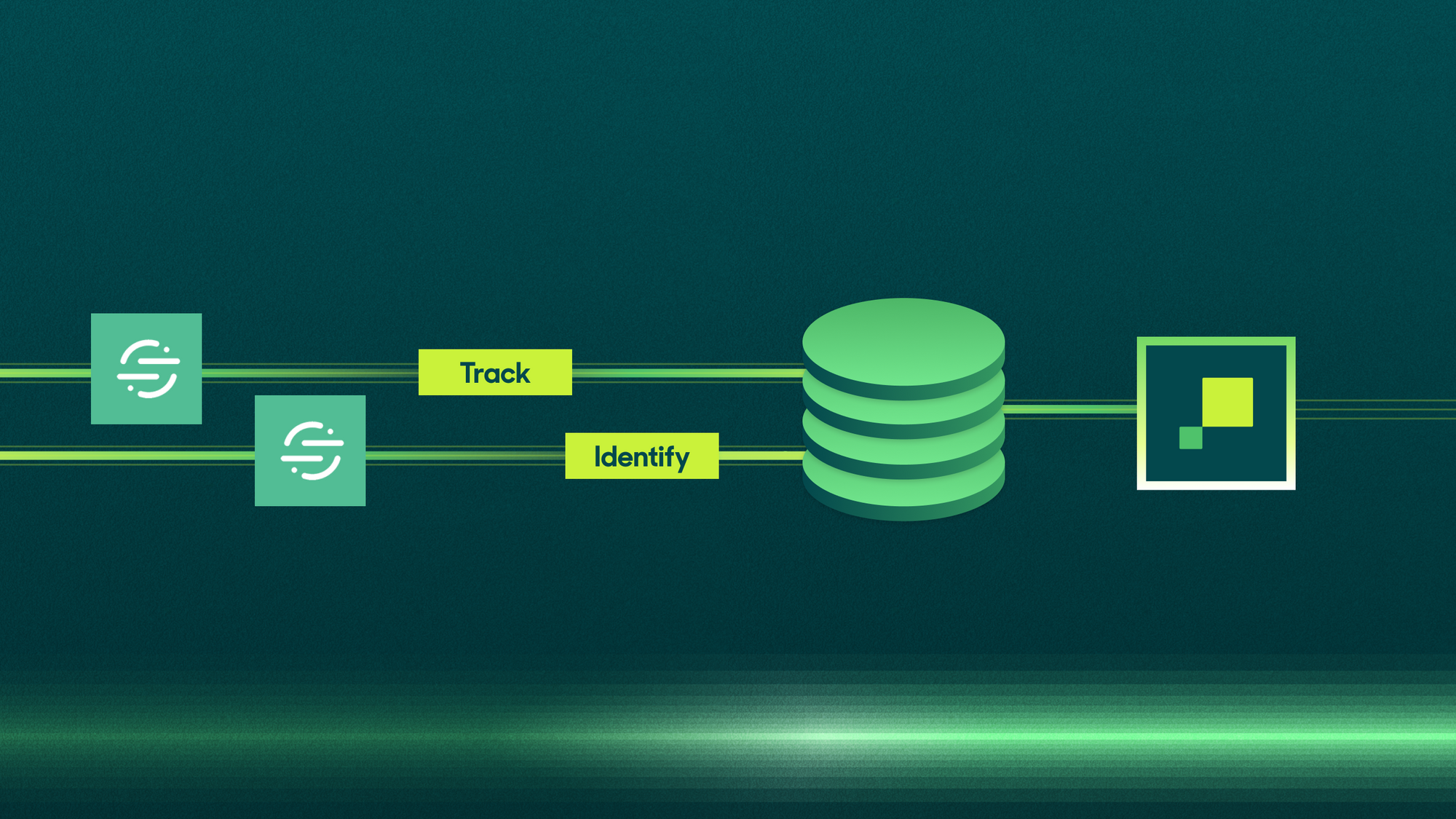
Let's say you're a data engineering team that wants all of your SaaS tools to have the data they need to be useful.
There are multiple solutions out there to help with this. A popular one is Segment which is known as a CDP (Customer Data Platform). Segment helps you fire user events from your product and sync data to a variety of your SaaS tools as well as to your Data Warehouse.
There's also Reverse ETL: the process of copying data from your warehouse to your SaaS tools through solutions like Hightouch. How do these solutions compare? The core difference is where your data is coming from: Reverse ETL solutions leverage your data warehouse as your source of truth, whereas Segment creates its own source of truth based on raw events tracked by analytics client libraries.
A powerful trend in the data community is to make your data warehouse the source of truth for all of the data. This allows you to create rich models and views in one place that combine data from multiple sources, such as a life-time value (LTV) field that combines a user's purchase data from Stripe as well as their product usage data.
If your team has been following this trend, and you have extensive models in your warehouse, then using CDPs like Segment leads to a dilemma on how you should get data into their SaaS tools. You can:
- Continue sending raw event data from a CDP like Segment that might not have the full picture of a customer that your tools need
- Or send modeled data from the data warehouse to your tools using a Reverse ETL tool like Hightouch.
The goal of this article is to help you understand:
- The similarities and differences between a CDP like Segment and a Reverse ETL tool like Hightouch
- The strengths of each
- And how the two work together.
Collecting Data vs. Activating Data
Segment, via its core product, Connections, allows you to collect data and sync the raw data to a variety of SaaS tools as well as a data warehouse.
Personas, Segment’s CDP offering, allows you to build user audiences based on the collected data, and sync these audiences to downstream SaaS tools. We believe that CDPs like Segment Personas are better off built on top of the data warehouse.

Hightouch, on the other hand, is solely focused on activating the data that is already in your data warehouse.
Unlike Segment, Hightouch cannot be used to collect data from your apps or to ingest data from third-party tools into the data warehouse. Most data teams using Segment use it to collect data from their website and apps, and use an ELT tool like Fivetran that is purpose-built to ingest data into a warehouse from cloud applications and databases. Segment and Fivetran are also complementary and companies that understand the value of making the data warehouse the source of truth tend to use both. For more information, you can check out this guide that covers the data integration landscape.

To summarize:
- Segment is used to collect event data from actions your users have taken in your apps
- An ELT tool like Fivetran ingests data into your warehouse from your SaaS tools and production databases
Now, the remaining step is to get customer data into the tools your business needs so that data can be put to use.
Getting Data Into Your Tools
As mentioned above, you have two key options for sending data into your tools:
- Continue sending raw event data from a CDP like Segment
- Or send modeled data from the data warehouse to your tools using a Reverse ETL tool like Hightouch.
Let’s discuss why you might want to consider sending data from your warehouse.
The Data Warehouse Has All the Data
Companies using a data warehouse such as Snowflake, Google BigQuery, or AWS Redshift tend to store all data from all sources in the warehouse. That is the core premise of investing in a data warehouse in the first place.
As per Segment’s CDP report for 2021, data warehouses are the third most-used cloud destination on the Segment platform -- proof that a bulk of Segment customers already sync data collected by Segment to a data warehouse.
Fivetran supports 100+ data sources including cloud applications for every function as well as all popular databases and its rapid adoption by data-forward companies has given it a billion-dollar valuation.
In short, data teams today have access to best-in-class tools to solve for every stage of the data pipeline -- from collection and ingestion to analysis and activation -- and the data warehouse lies at the center and acts as the source of truth for data.
The Data Warehouse Enables Modeling
It’s great to be able to store all the data in the data warehouse but to make sense of the data or derive insights from it, you need to model the data.
Modeling data in the warehouse refers to combining data from different sources and transforming the data into different formats for the purpose of analysis, and to do this, data teams typically use a purpose-built tool like dbt.
Being able to create custom data models enables you to bend and mold your data as per the requirements of downstream systems you want to send the data to. And the same data models powering reports on a BI tool can be used to power personalization in sales and marketing tools, enabling you to analyze and act upon the same data.
On the other hand, directly streaming raw data from tools like Segment to external apps poses certain limitations as the flexibility to combine and transform the data in a warehouse is lost. For example, you can use Reverse ETL tools like Hightouch to send an LTV model to Salesforce for upsells that combines a user's purchase data from Stripe as well as their product usage data. This wouldn’t be possible with Segment’s raw data approach. In many cases, we find that raw data is less useful than cleaned, transformed data.
Segment + Hightouch
If you’re already using Segment to collect raw user events, Hightouch and Segment can go hand-in-hand. You can leverage Segment for event collection and Hightouch as your Composable CDP. You can also leverage Hightouch for event tracking if you feel inclined.
Ultimately, you can choose what components you want to assemble around your warehouse and this is the value of the composable CDP. but want to take control over the data that your business teams use in their end tools (e.g., Salesforce, Marketo, HubSpot, Braze, NetSuite, Zendesk, etc.), you’re not out of luck. Segment and Hightouch can go “hand in hand.” In fact, tons of Hightouch customers use Segment to collect events and Hightouch as their data activation platform.
Hightouch can sync data to downstream tools as fast as it arrives in our data warehouse. For many of our customers using solutions like Fivetran, this is as low as 5 minutes. In the next few years, we expect warehouses to become truly real-time with technologies like Materialize and streaming support in Snowflake.
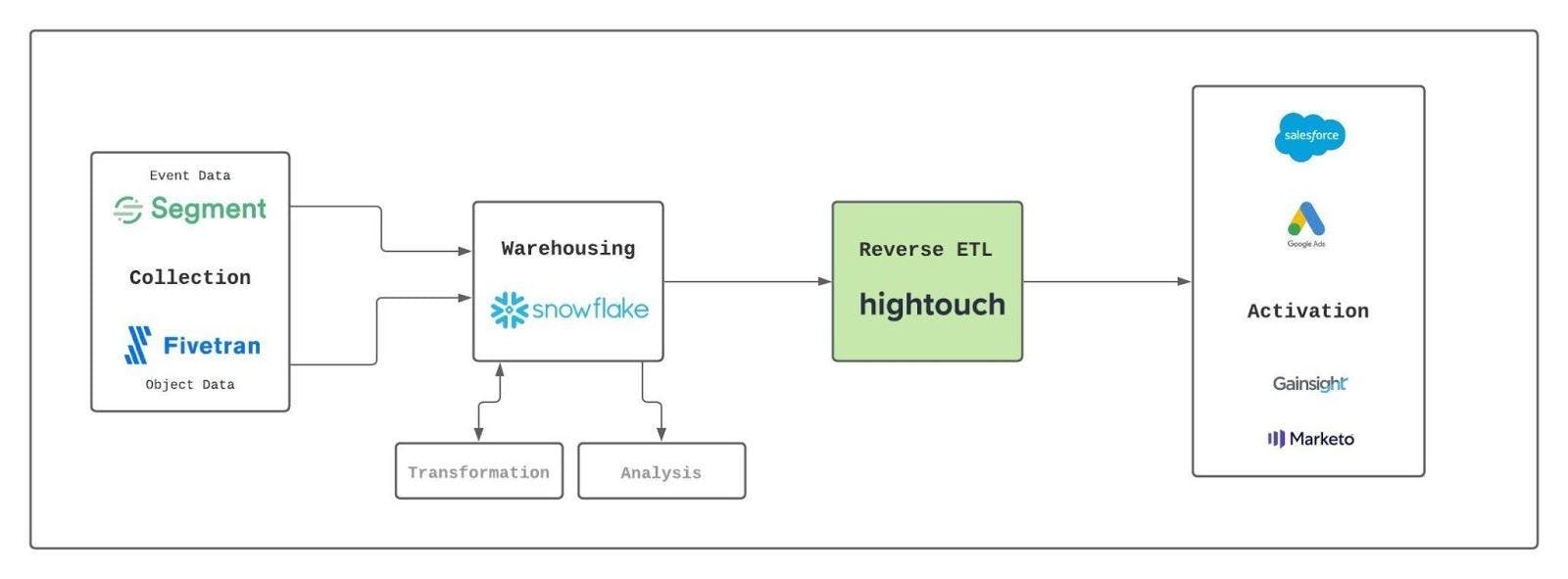
Segment and Hightouch are both core components of the Modern Data Stack
It helps to keep in mind that using a Reverse ETL solution like Hightouch doesn’t create a new workstream. If your data team is already building data models in dbt for the purpose of analytics, they can reuse those models via Hightouch to power operational workflows across your various business teams like sales, marketing, success, support, and finance. This maximizes the value of their existing data infrastructure investments.
Conclusion
Today, data teams at companies big and small are overwhelmed with requests for data and giving them access to best-in-class tools to fulfil those requests quickly and efficiently is a no brainer.
A Reverse ETL tool like Hightouch is a great fit for companies using Segment to track customer data and looking to activate the data residing in their data warehouse.
Whether you’re already using Segment or are figuring out which tools to include in your data stack, we would love to show you what we’re building at Hightouch to empower data teams to spend less time building integrations and more time solving problems core to your business. After all, data engineers should be helping solve business problems, not writing Reverse ETL.
Curious to see Hightouch in action or talk data? Book a demo — we’d love to show you around.