Why Every Tool in the Modern Data Stack Needs Git
Leverage the power of software development and DevOps and implement the same best practices you use in your production code in the context of data integration with Git.

Pedram Navid

Ernest Cheng

Luke Kline
November 9, 2021
4 minutes

Your data integrations aren't second-class citizens. They're as much a part of your infrastructure as the rest of your stack, and we believe they should be backed by the same choices as your production code. We know that developers can’t live without Git; it’s a core system of the modern developer workflow. Git’s ability to track iterative changes to code over time collaboratively is what has made dbt such a powerful tool in the data space.
That's why we believe every tool in the Modern Data Stack should be backed by a Git Integration.
The Hightouch Git Integration brings all the great features of Git to your Reverse ETL Workflows: commit logs of incremental changes, the ability to roll back to a previous state, and the ability to use code to create and edit Hightouch Syncs and Models. It’s just one step closer to bringing some of the powerful learnings from software development and DevOps to data.
It’s not just about keeping the lights on, it’s also about empowering developers. We know you hate clicking the mouse as much as we do, that’s why with we’ve built bi-directional Git Sync with support for creating and updating models and syncs straight from the command line. You get everything else git enables: the ability to perform CI checks, automated releases, pull-requests and reviews, and more.
Announcing Hightouch/Git Integration
Our new Git integration enables you to implement the same best practices you use for your production code in the context of data integration.
Features:
- Data Workflows as Code: Express your models and syncs as code, with an easy-to-read YAML schema
- Bi-directional updates: Maintain the existing user experience of easy configuration through the UI, or make changes and create resources via the CLI. It’s your choice, and it works both ways. No state conflicts, no compromises.
- Based on Git protocol: Our integration connects and works with all Git-based services that your teams already use like Github, Gitlab, and Bitbucket.
- Deep observability: You can easily see all edits to your syncs and models, and roll back unintended changes using all the power of git commands. You can effortlessly view all changes to your syncs in Git directly or in Hightouch.
- Edit syncs in Git or your CLI directly: Once you have created a sync in Hightouch, you can simply edit everything within your CLI in Git. Create a resource in the UI, and update it via the command line. Creating multiple copies of the same sync with slightly different parameters has never been easier!
How Does This Work Behind the Scenes?
When we built this integration, we had a few design choices that we believed were critical to its success. We wanted to create a native integration with Git that felt painless while avoiding some of the headaches that often come with other infrastructure-as-code projects.
State changes can be really hard to deal with and we didn’t want to force users to pick between making changes in the UI or via Git and the command line. Anyone who’s had a sleepless night trying to reconcile Terraform state changes before making a small change knows this pain all too well.
We also believed that observability and auditing should be first-class concepts. It wasn’t enough to simply sync changes between Git and Hightouch. We wanted to capture changes to all resources and commit those individually, to make roll-backs and cherry-picking easy. To that end, we came up with the following underlying architecture:
First, Hightouch implements syncing in two directions:
- Hightouch to Git (outbound)
- Git to Hightouch (inbound)
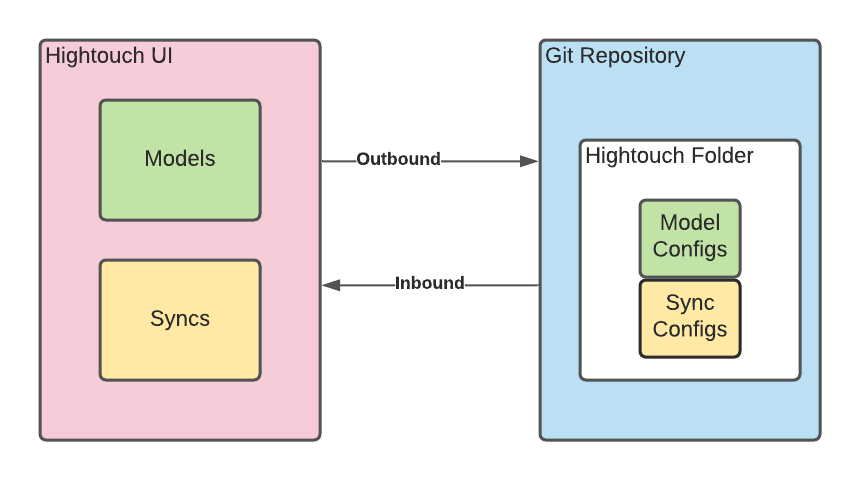
For the outbound direction, Hightouch keeps an audit log of changes made to all resources, e.g. configuration changes, schedule changes, and so on. On a fixed interval, we check the audit log to see which resources have changed and sync the new versions out to the Git repository.
We make an individual commit per resource, enabling users to roll back any unintended changes made in the Hightouch UI.
For the inbound direction, Hightouch looks into the Git repository and checks the state of every resource with the state in Hightouch. For each of those changes, we sync the new version into Hightouch, whether it’s a small change or a completely new resource.
There are some particular nuances that help us reduce the possibility of edge cases:
- We run the inbound sync, if and only if, the outbound sync was successful.
- We have added a required slug on every resource to help users identify resources. without the need for an uninformative ID. This is also useful if we’re creating resources directly inside Git.
How Do You Get Started?
Read our docs here to get started with Git Sync.